
Nous l’avons étudié dans le chapitre précédent. La mutualisation, le partage de liens a un intérêt technico-économique. Ne revenons pas dessus. Par contre nous avons également pu remarquer, que ce partage pouvait induire des dépassements des capacités en bande passante des supports. On est dans ce cas confronté à un problème de congestion.
Qu’est ce que la congestion …
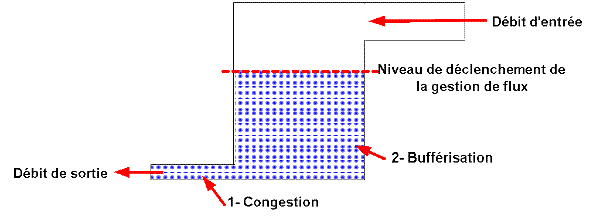
En fait la congestion apparaît dès que le débit utile d’un flux d’entrée (ou la somme des débits des flux d’entrée) est supérieure au débit utile de sortie.
C’est un peu comme si vous jouiez au ballon. Un camarade de jeu vous jette des ballons, vous devez les attraper, vous tourner et les lancer à un autre camarade, puis vous retourner vers le premier pour attraper un autre ballon :
- La fréquence à laquelle le premier vous envoi les ballons est le débit utile d’entrée.
- Le temps que vous mettez à vous tourner est assimilable au temps de traitement.
- La vitesse à laquelle vous transmettez les ballons à l’autre camarade est votre débit utile de sortie.
Dans cette image, il y a deux aspects intéressants :
- on comprend aisément que si l’émetteur des ballons accélère le rythme ou si plusieurs joueurs vous lancent des ballons vous risquez d’être rapidement débordé ! Résultat, vous allez perdre des ballons (ils vont tomber par terre !). C’est la même chose pour la transmission de données. Vous allez perdre des trames ! Vous êtes confronté à une congestion en entrée ! Le débit d’entrée est supérieur à votre capacité de traitement ! Si vous vous retourniez plus vite (l’image du traitement) vous pourriez prendre plus de ballons en charge !
- on peut également deviner que si votre capacité de traitement est supérieur, vous vous retournez plus vite pour passer vos ballons. Il est alors possible que le joueur à qui vous passez le ballon soit également débordé. Vos ballons vont tomber, vous êtes confronté à une congestion en sortie ! La capacité de traitement est supérieure au débit de sortie ! Il est intéressant de remarquer que plus vous êtes performant, plus vous risquez d’être en congestion en sortie !
Vous l’aurez compris, dans cette image, le joueur qui vous lance les ballons est le lien d’entrée, vous êtes l’équipement de commutation ou routage, l’autre joueur est votre lien de sortie !
Perdre des données, est-ce grave ?
Est-ce maintenant très grave de perdre des trames ? Oui et non !
On peut en perdre un peu, ça ne changera pas la face du monde, les protocoles sont là pour veiller à ces problèmes, il en résultera simplement une réémission des données par un des équipements de la chaîne (station émettrice ou équipement de commutation selon les protocoles et les architectures), nous avons vu cela dans le cours OSI.
Par contre si on en perd beaucoup, les réémissions constantes vont avoir pour résultat d’allonger le délai de réponse, un fichier qui devait être transféré en 10 secondes le sera en 20, 30 ou pire ! L’utilisateur derrière son écran recevra ses masques avec un délai insupportable, et vous … tombera sur le poil !
Enfin vous serez confronté à un dernier effet « pervers ». Plus il y a de congestion, plus vous perdez de données. Et plus vous perdez de données, plus il y a des tentatives de réémission par les protocoles, donc plus il y a de données à transférer et donc plus il y a de congestion ! L’effet « boule de neige », quoi !
Donc on ne peut pas laisser faire ! Il y a, peut-être, plusieurs méthodes pour s’en sortir :
- l’utilisation de buffers : méthode la plus basique mais qui ne va pas très loin !
- augmenter le débit : très facile mais pas vraiment du goût du directeur des achats ! D’ailleurs est-ce que cela sera efficace longtemps ?
- utiliser un support à bande passante variable : solution très intéressante ! Mais il y a encore mieux !
- utiliser un support à bande passante variable et asymétrique : de mieux en mieux ! On a un sens de transmission plus rapide que l’autre ! Mais quelle est la contre-partie ?
- mettre en place une priorisation des flux : hum … C’est vraiment très bien, mais attention à ce que l’on comprend par là ! Il y a des idées toutes faites que je vais me faire un plaisir de mettre par terre.
- mettre en œuvre une gestion de flux : Alors là, c’est imparable ! Bravo ! Oui, sauf que ça ne résouts pas le problème de congestion ! Le contrôle de flux s’active seulement s’il y a justement de la congestion !
Nous allons donc étudier ci-dessous ces différentes solutions.
Buffer ! Sauve-moi …
Soyons clair ! Tous les équipements de transmission sont équipés de buffers (mémoires tampons en français dans le texte !) en entrée et en sortie. Pour comprendre comment ça marche (alors là, je descends au niveau novice !) prenons une autre image que les ballons (les jeux de baballes n’ont jamais été ma tasse de thé). Utilisons l’image de la baignoire (ou du bac à douche, du lavabo ou de l’évier selon l’endroit où vous vous lavez !). La baignoire c’est sympa, un petit bain chaud j’aime ça de temps en temps (heu .. OK .. Vous vous en fichez !).
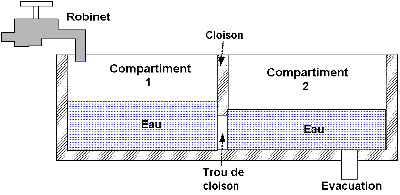 La baignoire c’est le buffer, le robinet c’est le lien d’entrée, l’eau c’est les bits et le tuyau d’évacuation c’est le lien de sortie (j’ai toujours dit que les télécoms n’étaient pas plus compliquées que la plomberie !). En plus notre baignoire est assez sympa parce qu’elle est prévu pour deux ! Mais pas de faux espoirs ! Il y a deux compartiments séparés par une cloison (pas de chance, hein ?). Cette cloison a un trou en bas qui permet à l’eau qui vient du compartiment 1, où est placé le robinet, de passer dans le compartiment 2, où est placé le tuyau d’évacuation ! Que se passe-t-il si on ouvre le robinet ?
La baignoire c’est le buffer, le robinet c’est le lien d’entrée, l’eau c’est les bits et le tuyau d’évacuation c’est le lien de sortie (j’ai toujours dit que les télécoms n’étaient pas plus compliquées que la plomberie !). En plus notre baignoire est assez sympa parce qu’elle est prévu pour deux ! Mais pas de faux espoirs ! Il y a deux compartiments séparés par une cloison (pas de chance, hein ?). Cette cloison a un trou en bas qui permet à l’eau qui vient du compartiment 1, où est placé le robinet, de passer dans le compartiment 2, où est placé le tuyau d’évacuation ! Que se passe-t-il si on ouvre le robinet ?
L’eau arrive dans le compartiment 1, s’écoule grâce à la pente (et oui ! Avez-vous déjà remarqué qu’il y avait une petite pente dans une baignoire ?) passe à travers le trou de la cloison, arrive dans le compartiment 2 et s’échappe par le trou d’évacuation ! Vous l’aurez compris, la taille du trou (et éventuellement l’inclinaison de la pente) symbolise ici la vitesse de traitement de l’équipement (heu … de la baignoire !). Que peut-il se passer ?
1. Les tailles du trou de cloison et du tuyau d’évacuation (j’oublie la pente que l’on considérera, bien … pentu !) sont supérieures à celle du robinet. L’eau passe sans problème dans le compartiment 2 puis s’échappe. Tout va bien !
2. La taille du tuyau d’évacuation est inférieure à celles du trou de cloison et du robinet (il y a probablement encore des cheveux dans le siphon ! Vous connaissez ça aussi, non ?). Par contre le trou de cloison est supérieur à la taille du robinet. Dans ce cas, l’eau s’écoule correctement dans le compartiment 2 où elle va s’accumuler puisqu’elle ne peut être évacué aussi vite qu’elle arrive ! Si vous arrêtez le robinet, l’eau du compartiment 2 va s’écouler doucement et il n’y aura pas de dégât. Par contre si vous continuez trop longtemps le compartiment 2 finira par déborder (le premier qui se lève pour m’opposer le principe des vases communicants est prié de sortir ! Je fais ce que je veux ! Dans MA baignoire il n’y a pas de vases communicants ! Compris ?). Vous avez donc dépassé les capacités de votre buffer de sortie !
3. La taille du trou de cloison est inférieure à celle du robinet. L’eau va s’écouler plus lentement dans le compartiment 2 qu’elle n’arrive par le robinet. Si le tuyau d’évacuation est supérieur à celui de la cloison vous n’aurez pas de remplissage du compartiment 2, par contre le premier risque de déborder si vous ne ralentissez pas le débit du robinet. Vous dépasserez dans ce cas les capacités de votre buffer d’entrée ! Éventuellement si le trou d’évacuation est dans le même temps inférieur au trou de cloison vous dépasserez également les capacités de votre buffer de sortie, le compartiment 2 va se remplir ! (La totale, quoi ! Sortez la serpillière, ça fuit de partout !).
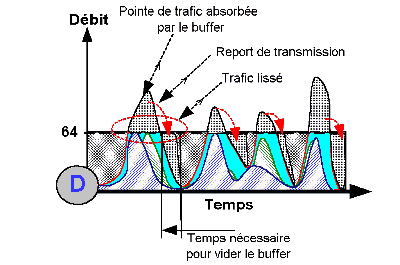 Vous l’aurez donc compris (du moins je l’espère), les buffers vous permettent de gagner un peu de temps, vous pouvez absorber une charge passagère mais pas constante, sinon vous obtiendrez également de la congestion !
Vous l’aurez donc compris (du moins je l’espère), les buffers vous permettent de gagner un peu de temps, vous pouvez absorber une charge passagère mais pas constante, sinon vous obtiendrez également de la congestion !
En fait, comme le montre le graphe D ci-contre issu du schéma du chapitre précédent, le buffer va reporter dans le temps la transmission d’une pointe de trafic momentanée. On parle souvent de « lissage » du trafic !
Et si on augmente le débit ?
L’augmentation de débit s’applique pour un problème de congestion en sortie, cela revient à augmenter la taille du tuyau d’évacuation de la baignoire ! Pour un problème de congestion en entrée il faut :
- soit diminuer le débit d’entrée (le directeur des achats est content, l’utilisateur beaucoup moins !)
- soit augmenter la capacité de traitement de l’équipement en congestion (ça va moins plaire au directeur des achats !)
En vérité on ne traite généralement que de problèmes de congestion en sortie ! En entrée on se limite à installer des équipements aux performances suffisantes pour absorber le débit d’entrée (ou la somme des débits d’entrée/sortie). Il est évident que pour transférer 2 000 ballons à la minute il vaut mieux avoir un lapin, qu’une tortue !
En supposant que vous ayez réussi à convaincre votre directeur des achats, qu’il est impératif, sous peine de révolte des utilisateurs, de monter en débit pour des problèmes de congestion en sortie. Pensez-vous avoir réglé tout vos problèmes ? Peut-être … Mais pas si sûr ! Avant de prendre cette décision il vous faut prendre en compte les remarques suivantes :
1. Quel type de trafic le lien véhicule-t-il ? Des données transactionnelles, du FTP, du SMTP ou de l’Internet/Intranet (HTTP) ? Peut-être un peu de tout ! Mais dans ce cas, quelle est l’application la plus dérangée et surtout quelle est l’application qui provoque la congestion ? Il vous faut en effet être conscient d’une chose : Vous pourrez monter aussi haut que vous voudrez en débit certaines applications utiliseront toujours la totalité de la bande passante disponible !
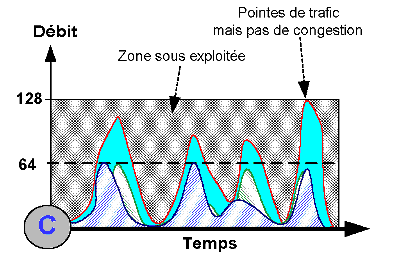
Ainsi un transfert FTP ou SMTP va monter aussi haut en débit que le permet la charge et la performance des serveurs et clients et bien sûr le lien d’interconnexion. Si vous montez en débit vous allez uniquement gagner sur le temps de transfert du fichier, qui va réduire (je précise, au cas où il y en aurait qui dormirait !). Nous sommes dans le cas du graphe C ci-contre. Votre zone inoccupée globale aura augmentée mais les pointes de trafic sont toujours là ! Une application transactionnelle qui discute en même temps qu’un transfert de ce type pourra donc en ressentir les effets …
Mais avouons tout de même que généralement l’effet est bénéfique ! Les transferts FTP sont plus rapides, la répartition du trafic est plus homogène et tout le monde est content … sauf le directeur des achats !
2. Mais, justement ! Tout le monde trouve ça super, et s’en donne à coeur joie ! Téléchargement de MP3, visio-conférences, pièces jointes de plusieurs méga-octets ! L’anarchie quoi ! Et quelques mois plus tard, vous êtes de nouveau en congestion ! Il sera donc peut-être nécessaire d’avoir une approche complémentaire à celle de la montée en débit … Nous y viendrons plus tard !
Donc, oui à l’augmentation de débit, mais non à l’embolie ! Si le lien est constamment chargé, il faut monter en débit, mais il faut d’abord savoir pourquoi !! Par contre, si vos liens ne présentent jamais de congestion vous pouvez en déduire que votre architecture est surdimensionnée !
Une bande passante variable, c’est possible ?
En effet, si l’on pouvait disposer d’un support de transmission qui soit capable de prendre en charge des pointes de trafic quand elles se présentent et de descendre à un débit minimal lorsque le trafic est calme, ce serait l’idéal ! On diminue ainsi fortement la zone inoccupée ! Bien sûr cela n’a d’intérêt que si ce support est moins cher qu’un support de débit égal à la pointe de trafic ! Sinon autant mettre des hauts débits partout !
Ce type de support existe, citons pour exemple : Frame Relay, ATM ou ADSL/TDSL (qui est de l’ATM en fait ! Nous y reviendrons !). Attention, ce sont plus des protocoles que des supports ! Rappelez-vous le modèle OSI, le support est au niveau 1, sa PDU est le bit ! Frame Relay et ATM ont des structures de blocs de données, c’est du niveau 2, même si ATM nécessite un complément de niveau 2 (la couche AAL).
Quoiqu’il en soit le principe est le même avec ces deux technologies (je considère que l’ADSL est assimilé à l’ATM, car en fait l’ADSL est une technique de transcodage des informations et n’a rien à voir avec la notion de débit variable !). Ce mode de fonctionnement induit trois nouveaux critères :
- le débit minimum (garanti ou non d’ailleurs) : c’est le débit que vous êtes certains d’avoir 100% du temps.
- le débit crête : c’est le débit maximum que vous pourrez obtenir
- le burst : c’est la capacité du support à maintenir le débit crête (pendant un certain temps).
Ce type de support présente généralement une tarification avantageuse par rapport aux supports à bande passante garantie car il permet aux opérateurs de dimensionner leur backbone sur la valeur d’un débit moyen (quelque part entre le débit minimum et le débit crête) d’accès. Cette valeur de débit moyen, et donc de dimensionnement du backbone, est d’ailleurs souvent un des critères de différenciation des opérateurs et de la qualité de service fournie.
Il est maintenant nécessaire de bien comprendre deux choses :
- ces technologies sont définies pour des connexions à un backbone. Mettre en place du Frame Relay sur une liaison point à point n’a pas beaucoup de sens (enfin presque … on peut séparer les services par CVP, mais ce n’est pas le sujet ici).
- le support d’accès au backbone doit être capable de fournir le débit crête ! Sinon à quoi ça sert ! On ne pourra jamais bénéficier des « bursts » autorisés par le backbone !
Un petit schéma vaut mieux qu’un grand discours ! Dans l’exemple ci-dessous, deux sites (A et B) sonr raccordés respectivement à 128 Kbps et 64 Kbps sur un lien de concentration lui-même dimensionné à 128 Kbps (soit donc en théorie sous-dimensionné). Pour le site A ont garanti un débit mini de 50% du débit crête (ici 128 Kbps), pour le site B le débit minimum garanti est de 32 kbps pour un débit crête à 64 Kbps. Les graphes A et B symbolisent la répartition du trafic dans le temps pour chaque site. Vous remarquerez que chacun d’eux dépasse allégrement le débit minimum par pointe de trafic. C’est les « bursts ».
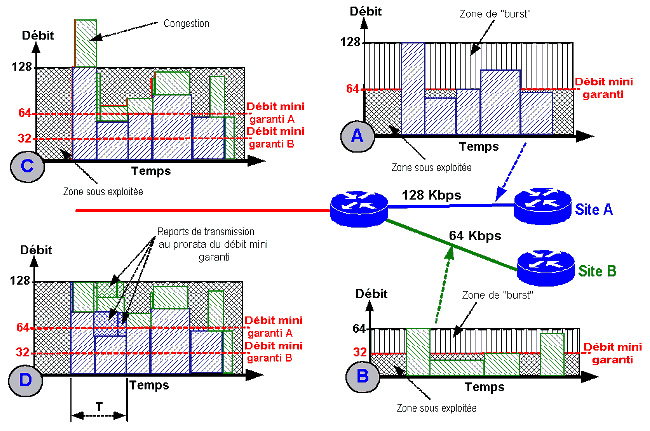
Le graphe C représente la somme théorique brute des trafics des deux sites. Vous remarquez la présence d’une congestion en début de graphe car la somme des débits nécessaires dépasse les capacités du support. Je précise (au cas où !) que le fait que le trafic vert soit empilé sur le bleu n’est qu’une vue de l’esprit ! Tous les paquets se mélangent bien sûr ! On pourrait ici laisser agir uniquement les buffers tel que nous l’avons décrit précédemment pour « encaisser » la charge passagère ! Mais ici le traitement est plus subtil !
Le graphe D symbolise l’action du mécanisme de bande passante variable sur le principe des « bursts ». Votre oeil exercé aura remarqué que le traitement est différencié en fonction de la provenance du trafic. La congestion sur le trafic « vert » est bien reportée dans le temps mais une partie est prise immédiatement en charge au détriment du trafic « bleu ». Résultat une partie du trafic bleu est réporté dans le temps également ! Examinons cela dans le détail :
- A ce moment T du trafic il faut acheminer 128K pour le trafic « bleu » et 64K pour le trafic « vert » sur un lien mutualisé à 128K max ! Nous avons donc une congestion d’une valeur de 64K !
- Le débit minimum garanti pour le trafic « bleu » est de 64K. Il est donc le double de celui du trafic « vert » qui est fixé à 32K. Par contre la somme des débits minimum est de 64+32 = 96K pour un lien capable d’acheminer 128K. Il aurait été dommage de limiter les deux trafics à leur valeur mini parce qu’il y a une congestion ! Il est plus intelligent d’exploiter les 32K de surplus en autorisant chaque trafic à dépasser légèrement son minimum autorisé.
- Il s’agit de répartir « équitablement » ce dépassement autorisé entre les deux trafics sur la base de leur rapport de débit minimum. Comme le débit minimum garanti du flux « bleu » est double de celui du flux « vert », le flux « bleu » aura droit à deux tiers du burst de 32K possible soit environ 21K supplémentaires, alors que le trafic vert aura droit au tiers restant soit donc 11K.
- Au total sur cette zone T, le trafic « bleu » aura bénéficié d’une bande passante de 85K (64+21) et le trafic « vert » d’une bande passante de 45K (32+11) ! Le surplus de trafic de chaque flux soit donc 43K pour le « bleu » et 19K pour le « vert » est reporté dans le temps par la mise en buffer !
Cette démonstration permet d’émettre les constatations suivantes :
- La méthode de mesure du burst, de surveillance du débit minimum et de répartition égalitaire des dépassements relève du principe de bande passante variable du protocole (Frame Relay ou ATM). Chaque protocole utilisera son propre mécanisme et ses propres définitions, par exemple en Frame Relay on parlera de CIR pour le débit minimum et la gestion de « burst » sera réalisée sur la base d’un calcul de temps de transmission et de nombre de trame (voir de volume de données mais c’est plutôt rare !). En ATM on parlera par contre de SCR pour le débit minimum, de PCR pour le débit crête et de MBS correspondant à un nombre de cellules pour la capacité du burst !
- Dans tous les cas, la fonction de report du trafic dans le temps relève de l’action des buffers ! Par contre il sera également nécessaire de prévoir au niveau protocolaire un accord et une méthode pour décider du principe de suppression des trames en surplus en cas de débordement des buffers. En ATM et en Frame Relay on marque les trames (ou cellules) considérées comme au-delà du débit minimum. On parle de « tag » pour le marquage (bits FECN et BECN en Frame Relay par exemple).
- Dans l’exemple ci-dessus vous avez pu remarquer que les flux « bleus » et « verts » bénéficient au global d’un débit supérieur situé entre leur minimum garanti et leur débit crête ! On parle de débit moyen. Plus le lien mutualisé sera surdimensionné, plus le débit moyen sera élevé ! C’est souvent ici que la différence de qualité de service se joue entre les opérateurs ! Le plus gros backbone l’emporte à ce jeu !
- Pour terminer, vous avez remarqué que la gestion du trafic est différenciée en fonction de la source. L’équipement sur le lien mutualisé gére différemment l’allocation de bande passante selon que le trafic était « bleu » ou « vert ». Ceci suppose que le protocole est donc capable d’identifier le trafic et que l’équipement a connaissance des paramètres appliqués à chacun d’eux (notamment en terme de débit minimum garanti !). En Frame Relay on parlera de CVP (Circuit Virtuel Permanent) alors qu’en ATM on parlera de VC (Virtual Circuit), voir de VP (Virtual Path). On parle également de « contrat de trafic » ou encore de « shapping« .
Une bande passante asymétrique, c’est vraiment mieux ?
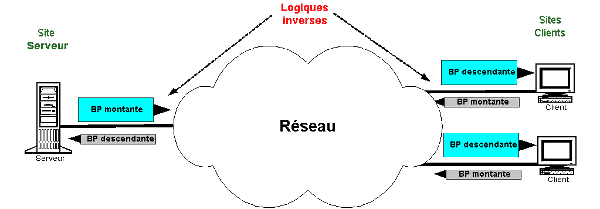
Oui ! Sans conteste, dans 90% des cas !
En effet, 90% des informatiques fonctionnent de la même façon … Il y a quelque part un utilisateur derrière un écran et un clavier (ou quelque chose qui y ressemble !) qui entre des données et attend des résultats sur son écran ou son imprimante. Généralement les données sont envoyées à un serveur qui répond (quand il a le temps !).
Souvent les réponses serveurs sont plus volumineuses que les requêtes clients (utilisateurs). Donc le trafic montant vers le serveur est plus faible que le trafic descendant vers le client. Si le serveur est accessible par un réseau, il serait intéressant, pour le site hébergeant les clients, de disposer d’un débit plus important pour le trafic venant du réseau (et donc du site serveur) que celui montant vers le réseau (et donc vers le site serveur). Par contre pour le site serveur c’est l’inverse ! Il a besoin de livrer plus de trafic que d’en recevoir !
Citons pour exemple les applications de transfert de fichiers type FTP (à partir du moment où le transfert se fait d’un serveur vers un poste client, et pas entre serveurs !), les applications transactionnelles vers des bases de données, la consultation de boite aux lettres (POP3 ou IMAP4), encore qu’il faille relativiser car quand on envoi une grosse pièce jointe le volume montant peut être important, etc …
Bien sûr ceci ne s’applique pas à tous les types d’applications, par exemple quand il s’agit de réplication ou de mirroring de serveurs les flux sont importants dans les deux sens ! Il en va de même pour le trafic entre serveurs de messagerie ou les applications d’intégration voix-données ou visioconférence !
La bande passante asymétrique était déjà disponible depuis longtemps avec des technologie comme le Frame Relay (CVP à CIR asymétriques) ou l’ATM mais les supports à bande passante asymétrique ont pris leur envolée récemment avec l’arrivée de l’ADSL ! En effet, l’ADSL (Asymetric Digital Subscriber Line) est une méthode d’encodage des données sur un support (un transcodage … rappelez-vous le cours OSI, couche Physique !) qui offre l’avantage :
- d’utiliser la partie haute de la bande de fréquence des supports cuivres. On transcode le signal dans une bande de fréquence en dehors de la bande 300-3400 Hz utilisée par la voix sur le support téléphonique. Ceci permet donc de transmettre des données sur une ligne en même temps qu’on parle ! Cool non ? (C’est pour ça messieurs que vos femmes acceptent de payer vos abonnements ADSL ! Elles peuvent continuer de passer des heures au téléphone avec leurs copines !). Par contre il y a une contrainte de distance car à cette fréquence, l’affaiblissement du signal est important et au-delà de quelques Km d’un point de régénération il n’y a plus de signal !
- de proposer un débit asymétrique ! La bande porteuse montante vers le réseau ne peut pas encoder aussi vite que la bande descendante et donc le débit est moindre ! De manière optimale on obtient un débit montant (du site vers le réseau) à 800 Kbps pour un débit descendant (du réseau vers le site) à environ 2 Mbps.
- d’assurer un débit binaire variable en fonction du contrat de trafic ATM (niveau 2 implémenté sur le niveau 1 ADSL) proposé par l’opérateur, ce qui permet à celui-ci d’afficher plusieurs types d’accès ADSL en fonction des débits maximum proposés. Ainsi France Télécom, propose un accès Netissimo 1 à 512 Kbps en réception et 128 Kbps en émission et un Netissimo 2 qui double ces valeurs, soit 1024 Kbps (1Mbps) et 256 Kbps !
Par contre en dehors de la limitation de distance, qui oblige à procéder à une étude d’éligibilité au service ADSL avant d’y souscrire, une autre contrainte apparaît, peu sensible dans le cas de l’Internet, mais rédhibitoire pour certaines applications : le délai de transit !
En effet, l’ADSL est la technique d’encodage du signal, c’est donc du niveau 1 ! Sur le niveau 1 on place un niveau 2 (couche Liaison, rappelez-vous le modèle OSI !). Cette couche est une couche ATM qui elle-même nécessite une sur-couche AAL pour véhiculer du trafic comme IP par exemple. Or en ATM, la norme défini la MTU à 48 octets sur une cellule de 53 octets (une trame quoi !). Vous imaginez donc bien qu’on est obligé de fragmenter les paquets, ce qui induit un retard non négligeable dans la transmission. A ceci s’ajoute l’enchaînement des équipements de collecte du trafic qui n’arrange pas les choses.
Si vous utilisez des applications qui profitent largement d’une bande passante importante (transferts de fichiers, client-serveur en mode non connecté, transactionnel en mode page) il n’y a pas de problème. Le gain en bande passante compense largement l’augmentation du délai de transit et au final c’est plus rapide ! Par contre si vos applications sont de type client-serveur en mode caractère ou champ par champ, ou encore si vous utilisez des systèmes d’émulation comme CITRIX ou Terminal Server, les effets peuvent être sidérants ! Il est préférable de procéder à un test ! En effet, ce type d’application est réputé n’avoir pas besoin d’une grosse bande passante, donc elles n’utilisent pas celle mise à disposition, et l’utilisateur ressent de plein fouet l’augmentation du délai de transit !
Pour résumer :
- L’asymétrie de débit est un réel avantage. Pour un site client on préférera une bande passante importante pour le trafic descendant du réseau. Pour un site serveur on préférera une bande passante importante pour le trafic qui monte vers le réseau.
- La technologie de prédilection pour ce type d’accès est l’ADSL (ou Turbo DSL) mais attention : la bande passante importante est toujours descendante du réseau, ceci est donc inadapté pour un site serveur
- des contraintes de distances fortes empêchent parfois son utilisation pour certains sites « perdus »
- le délai de transit peut nuire à certaines applications
- Rappelons que la couche ATM fournie permet en plus d’offrir une bande passante variable telle qu’étudié dans le paragraphe précédent.
Prioriser le trafic, est-ce une bonne solution ?
Soyons clair ! De nombreux concepteurs voient là une méthode idéale pour contrôler la congestion ! C’est faux !
| La priorisation pour la congestion, c’est un peu comme l’aspirine pour la rage de dent !
Ca calme un peu la douleur, mais ça ne soigne pas la carie ! |
Nous l’avons vu, le coté nuisible et pénible de la congestion est qu’elle ralentie le trafic, puisqu’elle oblige à buffériser et donc reporter la transmission. Nous avons vu que si celle-ci se prolonge il va y avoir « over full in buffer » ! Le résultat est une perte de données, qui nécessite une réémission par les protocoles, et donc un ralentissement de transmission du point de vue utilisateur …
Si ces effets sont toujours indésirables, nous avons vu qu’il fallait relativiser … Pour des transferts de fichiers ou de la messagerie, l’allongement de quelques millisecondes sur le délai de transmission ne mérite pas d’en faire un fromage ! Par contre, si l’application est de type transactionnelle champ par champ ou mode caractère (voir émulation graphique) il est fort possible que ce ralentissement soit directement ressenti par l’utilisateur qui va vous … tomber sur le poil !
Nous avons également vu que dans une certaine mesure vous pouviez envisager d’utiliser des supports favorisant la prise en charge de pointes de trafic ou même envisager une montée en débit, si vous avez d’excellentes relations avec votre directeur des achats (ce qui est extrêmement rare … ce sont généralement des gens irascibles et infréquentables 😉). Malheureusement le prix du Kbps n’est pas anodin et il serait dommage d’envisager une modification du support pour absorber des surcharges épisodiques !
Dans ce cas, la priorisation peut vous aider ! Le principe est simple ! En cas de congestion, et en cas de congestion SEULEMENT, les équipements de transmission vont autoriser la transmission en priorité de certains flux par rapport à d’autres qui seront retardés (bufférisés). Vous allez donc programmer vos équipements d’interconnexion pour qu’ils analysent le type de trafic qui leur passe sous le nez et qu’il classifie (on dit aussi marquer ou colorier) dans un niveau de priorité élevé le trafic de vos applications sensibles pour les utilisateurs (ou pour l’entreprise … quelquefois les vues sont divergentes à ce propos !!). Lorsqu’il y a congestion cet équipement transmet d’abord les données des flux prioritaires. Cela paraît simple, le principe l’est, mais ses déclinaisons et sa mise en œuvre beaucoup moins ! Par exemple :
- Combien de niveau de priorité sont définis ? Vous pouvez être tenté de définir plus de deux niveaux de priorité, par exemple le très prioritaire, le prioritaire, le moyennement prioritaire, le presque pas prioritaire et le pas prioritaire du tout (qu’est ce qu’on se marre, dans le réseau !). Tout de suite on sent le problème ! Il va falloir définir plusieurs files d’attentes en fonction de la priorité … Bonjour les besoins en mémoire !
- Tout de suite derrière se pose la manière de vider ces mémoires tampons ! Je commence à vider le prioritaire uniquement quand j’en ai fini avec le très prioritaire ? Ca paraît raisonnable ! Mais si mon trafic très prioritaire est constamment présent ? Le moins prioritaire peut aller se coucher ? On appelle ce phénomène, la famine ! Le trafic moins prioritaire n’est plus acheminé, il y a un manque quelque part (pour un utilisateur par exemple). On dit « famine » parce que le trafic prioritaire « mange » toute la bande passante (Le goulu ! L’égoïste !).
- Donc on essaie de mettre en place quelque chose de plus « humanitaire« . On accorde au trafic le plus prioritaire une part garantie de bande passante (par exemple 50%) et à chaque classe de trafic (niveau de priorité) une part répartie sur le reste. Par exemple pour trois classes de trafic on utilisera une répartition 60-30-10 ! Ainsi même le trafic « bas de classe » est sûr de pouvoir passer … un peu ! C’est l’idéal n’est ce pas ?
- OK ! C’est beau ! Mais si je n’ai pas de trafic prioritaire mais que la charge engendrée par le trafic non prioritaire génére une congestion ? Je sous-emploie 50% de ma bande passante (les 50% réservés au trafic prioritaire) ? Bonjour le gaspillage ! Donc il faut que je fasse de la répartition de bande passante dynamique ! Tout ce qui n’est pas utilisé par une classe peut l’être par une autre ! OK … On commence à approcher de la perfection …
- Mais il y a encore d’autres aspects complexes dans la prioritisation comme la manière dont on doit s’y prendre pour éviter l’engorgement des buffers de chaque classe ! Dois-je attendre d’être « full » ou est-ce que je commence à alléger le trafic avant l’engorgement en supprimant des paquets ? Dois-je plutôt supprimer des gros ou des petits paquets ? Etc, etc. Arrêtons-nous là !
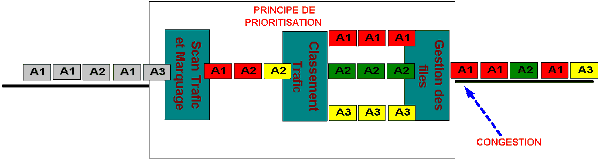
Vous l’aurez compris, ça paraît simple, mais c’est en fait loin de l’être ! Les algorithmes sont extrêmement complexes et les ressources (CPU, mémoires) sont importantes ! Pour résumer :
- La priorisation n’est pas une réponse à une charge massive d’un réseau ou d’un lien. Seul l’upgrade en débit est la réponse dans ce cas !
- La priorisation est une solution complexe à mettre en oeuvre et qui ne doit agir que pour maintenir une qualité de service la plus constante possible pour des applications sensibles en diminuant l’effet néfaste des congestions passagères (pointes de trafic) qui ne justifient pas d’un upgrade.
- Dans certains cas, la priorisation est une arme absolue pour mettre un frein à la frénésie des utilisateurs gourmands en bande passante ! J’ai le cas d’un client qui bridait ainsi la bande passante Internet par utilisateur à 10 Kbps (adieu le MP3 !). Il était ainsi sûr de garder la bande passante nécessaire pour son Oracle !
- Les équipementiers implémentent tous des mécanismes de priorisation, propriétaires ou non, sur leurs matériels. Les fonctions offertes sont plus ou moins élaborées selon les cas.
Enfin je voudrais attirer votre attention sur le problème de correspondance entre les politiques de priorisation de niveau 3 et la gestion de bande passante variable telle que nous venons de la voir. Je ne peux pas développer ici ce problème, mais essayez d’imaginer le problème suivant : Si je bufférise une trame Frame Relay par exemple, comment savoir si celle-ci ne contient pas un paquet prioritaire ? Pire, je pourrais même supprimer cette trame parce que mes buffers sont pleins et que le contrat de trafic est dépassé ! Des paquets prioritaires placés dans des trames émises dans la zone de « burst », et donc candidates à la suppression ou au rejet, sont donc susceptibles de ne pas être acheminés … L’idéal serait que je place mes paquets prioritaires dans des trames comprises dans la zone de bande passante garantie … Mais pour que la priorisation soit activée il faut que le support soit considéré en congestion ! Si je défini le niveau de congestion à la valeur du débit garanti au lieu du débit « burst » je me prive de la possibilité de « burster » !
Et oui ! Pas facile, tout ça …
Et la gestion de flux ? Est-ce la réponse universelle ?
Tout d’abord précisons les choses ! La gestion de flux en soit est une notion très vague et très large ! Les mécanismes de « bufferisation » ou de gestion de bandes passantes variables tels que nous venons de les étudier sont eux-mêmes des mécanismes de gestion de flux !
La gestion de flux, appelée aussi contrôle de flux, dont je veux vous entretenir ici, relève plus de mécanismes protocolaires permettant à un équipement surchargé de demander à une source de trafic de ralentir ou stopper ses émissions. Dans ces conditions, il est important de comprendre une chose :
| Le contrôle de flux n’est pas un moyen d’éviter la congestion, il permet de gérer le problème du risque de perte de données quand il y a une congestion grave (qui dure !). |
Le contrôle de flux sera activé par un équipement lorsque ses buffers atteindront un certain niveau de remplissage (disons 80%). Afin d’éviter que les nouvelles données viennent écraser celles déjà en attente dans les registres mémoires, ce qui revient à perdre des données, l’équipement va activer différents protocoles pour calmer les ardeurs des émetteurs !
Lors du cours OSI nous avons abordé ces notions et je vous ai notamment fait remarquer que la gestion de flux pouvait être mise en œuvre à plusieurs niveaux OSI :
- au niveau 2, couche liaison de données, cette gestion s’applique sur tout le trafic échangé entre deux équipements directement connectés à travers un support physique. Le protocole de niveau 2 (HDLC, PPP, Frame Relay, etc.) offre des mécanismes qui permettent de ralentir ou stopper l’émission des trames par l’émetteur lorsque le récepteur est surchargé. A ce niveau le contrôle s’applique donc uniformément pour l’ensemble du trafic de niveau 3 véhiculé par les trames de niveau 2. Il n’est pas possible à ce niveau de ralentir telle ou telle station qui « s’emballe » ! Le problème est ici que si le récepteur demande à l’émetteur de stopper son émission, l’émetteur continue de recevoir le trafic sur sa propre entrée ! Il risque de passer également en congestion et devra demander à son propre émetteur de stopper également sa transmission. On remontera ainsi petit à petit la chaîne jusqu’au point source de l’engorgement … Nous avons à faire à une gestion de flux de proche en proche ! Mais, en attendant, on aura bloqué le trafic de tous les sites utilisant le lien alors que certains émettaient « raisonnablement » ! A noter, qu’en Frame Relay l’avantage est qu’on identifie précisément les sites émetteurs par le CVP attribué. La gestion de flux est donc moins totale ! Mais en Frame Relay le principe n’est pas de bloquer l’émetteur mais de supprimer les trames en trop !
- au niveau 3, couche réseau, cette gestion s’applique à une communication de niveau 3 donnée et non plus à l’ensemble du trafic entre deux équipements au niveau 2. Le protocole de niveau 3 est donc capable d’identifier le circuit (X25) ou l’adresse de l’émetteur (IP) pour appliquer un contrôle de flux au trafic de ce seul émetteur. Le contrôle de flux est donc « plus fin » mais nécessite une gestion plus complexe, plus gourmande en ressource. On pourrait penser, en regard de cette explication, que le contrôle de flux de niveau 3 est donc un contrôle de bout en bout. En fait ce n’est pas forcément le cas, car : l’équipement en congestion qui émet les ordres d’arrêt à l’émetteur n’est pas forcément la station de destination finale du trafic, ce peut être un commutateur ou routeur intermédiaire.
- le contrôle peut également s’appliquer de proche en proche comme c’est le cas en X25. C’est à dire que le commutateur qui est submergé informe le commutateur précédent qu’il ne prend plus en charge le trafic lequel informera le précédent, ainsi de suite jusqu’à la station émettrice. L’information ne remonte donc pas directement à la source !
- au niveau 4, couche transport, le contrôle s’applique de processus à processus, et ne nous concerne pas sur un plan réseau. Ainsi, par exemple, un transfert FTP sera régulé alors qu’un transfert HTTP ne le sera pas même si ces transferts ont lieu simultanément entre les deux mêmes machines. Le contrôle ici est bien de bout en bout par contre dans tous les cas.
- au niveau 5, couche Session, le contrôle de flux s’applique également pour des processus ou des travaux identifiés, mais ceci relève de l’informatique plus que du réseau … Laissons tomber !
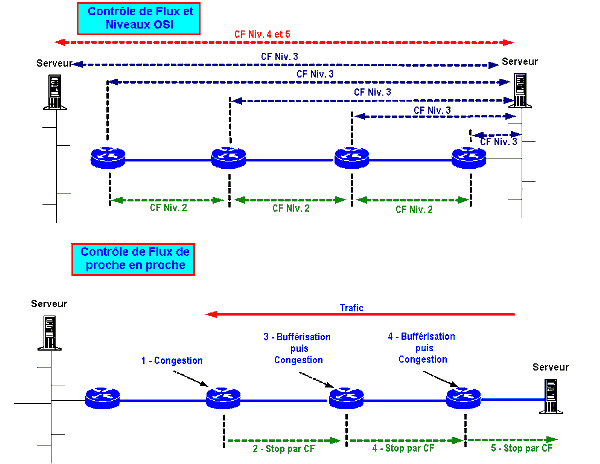
Au final, à quel niveau le contrôle de flux est-il donc le plus adapter ? En vérité : Aucun et Tous ! Comme nous venons de le voir, à chaque niveau son utilité :
- Le contrôle de flux de niveau 2 pourra régler des problèmes de congestion du lien et éviter ainsi de dépasser des seuils de « bursts » par exemple qui auraient pour effet d’amener à de la perte de trames.
- Le contrôle de flux de niveau 3 réglera les problèmes de congestion pour respecter des contrats de trafic de répartition d’utilisation de la bande passante par communication de niveau 3.
- Le contrôle de flux de niveau 4 pourra veiller à ne pas dépasser les capacités de bufférisation des stations destinataires en informant les émetteurs directement d’une charge pour un process donné.
En résumé :
- Le contrôle de flux est la réponse obligatoire à un service de transfert de données offrant un minimum de qualité de service. Il permet d’anticiper le dépassement de capacité des buffers des équipements de la chaîne de données avant d’arriver au niveau de pertes ou rejet de données.
- Il existe du contrôle de flux pour les principaux niveaux OSI (2, 3 et 4). Chacun contribue à diminuer le risque de pertes de données avec une portée différente.
- Le contrôle de flux n’est pas la réponse à une congestion ! Il s’active au remplissage des buffers ! La congestion est donc déjà présente ! Mais il y a risque de dépassement du contrat de trafic et d’écrasement des données dans les buffers, voir quelquefois de « plantage » complet des équipements !
Enfin, il existe de nombreux mécanismes, ou principes, de contrôle de flux, on parle de contrôle par crédit ou par fenêtre ou encore par anticipation, tout cela étant le même chose, on parle également de contrôle de proche en proche ou de bout en bout, de mode caractère (Xon/Xoff), ou par fil (105/108), bref ! Ce n’est pas le but de ce paragraphe ou ici nous étudions l’utilité d’un contrôle de flux dans le cadre d’une congestion.
Conclusion du chapitre
Un très, très long chapitre que j’espère, vous n’avez pas trouvé trop ennuyeux ! Mais il me semblait important d’aborder cette notion de congestion et de contrôle de congestion qui est en fait le résultat direct d’une mutualisation des ressources réseaux et donc une problématique fondamentale à aborder lors de la constitution d’un backbone mutuel !
En conclusion, retenez ceci :
- La congestion est un résultat normal à la mutualisation des ressources.
- On ne doit pas chercher à la supprimer complètement car elle existera toujours par pointe de trafic.
- Il s’agit de faire la différence avec un problème de charge global qui occasionne une surcharge constante des liens et une bufférisation constante des données. Dans ce cas la seule solution est l’upgrade des liens (et/ou équipement) ou l’utilisation de type de support différents comme des supports à bande passante variable et/ou des supports à débits asymétriques.
- Les mécanismes de priorisation et de contrôle de flux ne sont pas des solutions diminuant la congestion mais permettant de contrôler ses effets néfastes (délai de transit et pertes de données).