
Une solution de secours doit bien sûr permettre à un site de rester connecter à son réseau même si son raccordement nominal est hors service.
Le principe de base est donc extrêmement simple ! Lorsque le routeur du site détecte que la connexion nominale vers le réseau est Hors Service il bascule sur la solution de secours. Mais comment le routeur sait-il que le lien vers le réseau (ou le réseau) est hors service ?
La sortie du LAN
Notre objectif étant de permettre à un site de continuer d’émettre même si son raccordement au réseau est hors service, rappelons tout d’abord à vos esprits surchargés les principes de routage pour sortir un paquet IP de son LAN d’émission (déjà évoqués dans le cours IP).
Lorsque vous installez un équipement IP sur un LAN vous renseignez dans sa configuration au minimum 3 paramètres :
– son adresse IP sur le LAN
– son masque d’adresse. Je rappelle que cela lui permet de savoir dans quel réseau IP ou sous-réseau il est placé
– l’adresse IP de la Gateway de sortie du LAN (le routeur) à qui il doit envoyer ses paquets si ceux-ci ne sont pas à destination de son LAN IP local.
Rappelons également (on ne sait jamais) que le paquet IP va être encapsulé dans une trame de niveau 2 (souvent Ethernet !) pour être émis sur le LAN vers le routeur. Cette trame à une adresse de destination (entre-autre !), dite « adresse MAC ». La première fois que l’équipement IP devra émettre un paquet IP au routeur (gateway) il ne connaît que son adresse IP, pas son adresse MAC ! Il va donc procéder à une résolution ARP (vous vous souvenez ??) pour découvrir cette adresse. Il l’a mémorise ensuite dans sa table ARP. Il peut donc maintenant envoyer son paquet IP au routeur.
Voilà ! Les cervelles sont rafraîchies maintenant ! N’oubliez pas ce concept parce qu’on y reviendra plus tard ! Et maintenant passons à la suite …
Détection d’indisponibilité du raccordement nominal
Quel que soit le type de raccordement du site au réseau (LL, SDSL, IP/ADSL, RNIS, etc …) on retrouve une constante ! Le routeur est connecté à un organe d’accès (PoP, NAS ou BAS) via une connexion de niveau 2 (PPP, HDLC, Frame Relay, ATM, etc …). Je vous renvoie à l’excellent Cours OSI pour vous rafraichir la mémoire si nécessaire !
Il existe donc un échange de niveau 2 entre le routeur et l’équipement d’accès, le routeur place ses paquets IP dans la trame. Donc, si la liaison physique (LL, SDSL, RNIS, etc …) est coupée (rupture du parcours filaire, modem hors service) la connexion de niveau 2 est rompu et le routeur le sait ! Il peut donc engager une procédure de secours.
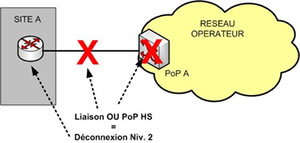 Si le PoP de raccordement passe Hors Service (problème EDF ou site bombardé par un opérateur concurrent !) la connexion de niveau 2 est également hors service !
Si le PoP de raccordement passe Hors Service (problème EDF ou site bombardé par un opérateur concurrent !) la connexion de niveau 2 est également hors service !
Détection d’indisponibilité du backbone
Ici ça se complique … Nous pouvons très bien envisager le cas « rare » où le backbone de l’opérateur rencontre un problème. Les réponses varient en fonction de la nature du réseau backbone. Nous devrons envisager plusieurs cas :
– Le réseau backbone est de niveau 2 (Frame Relay, LL, Ethernet, etc …)
– Le réseau backbone est de niveau 3 (IP pur, MPLS)
Backbone Frame Relay
Nous avons de la chance ! Avec Frame Relay il est extrêmement simple pour le routeur distant de détecter s’il y a un problème dans le backbone !
En effet, comme l’indique le schéma ci-dessous, la connexion de niveau 2 est établie de bout en bout à travers le réseau backbone. Il s’agit d’un CVP (Circuit Virtuel Permanent ou PVC : Permanent Virtual Circuit for english spoken).
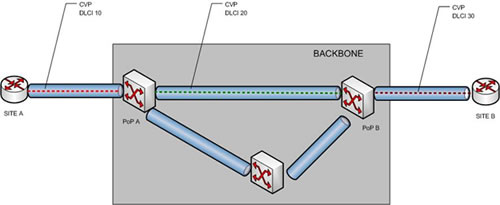
Dans la réalité ce n’est pas tout à fait juste … Un CVP est une succession de plusieurs circuits mis bout à bout à travers le réseau. Entre chaque équipement relais (commutateur Frame Relay) un circuit est établi. Le commutateur transfère les trames selon une table de commutation renseignée manuellement.
Dans le schéma ci-dessus un CVP « rouge » est créé entre le routeur A et le PoP A et un CVP « vert » entre le PoP A et le PoP B. Chaque CVP est identifié par un numéro (inscrit sur la trame Frame Relay) appelé DLCI (Data Link Control Identifier).
Dans la table de routage du routeur A, une entrée indique que tout paquet à destination de B doit être placé dans une trame Frame Relay avec un DLCI 10 et émis sur son interface de sortie S0 (par exemple). Je sais que vous avez lu avec attention le cours « Routage IP », je ne vous rappellerai donc pas comment cette table a été renseigné !
A la création du réseau, l’opérateur a construit dans le backbone les liens virtuels ! Il a donc indiqué au PoP A :
– qu’il existe une connexion virtuelle avec le Site A via un DLCI 10 sur son interface S0 (par exemple)
– qu’il existe une connexion virtuelle avec le PoP B via un DLCI 20 sur son interface S1( par exemple)
– qu’une commutation entre les trames DLCI 10 sur S0 et DLCI 20 sur S1 doit être réalisée.
L’aboutement des deux CVP est donc réalisé ! C’est la même chose coté PoP B et site B.
Maintenant supposons que le lien entre le PoP A et la PoP B passe hors service. La connexion de niveau 2 entre ces deux PoP va être rompue. Mais les routeurs A ou B ne le sauront pas puisque leurs connexions à leurs PoP respectifs seront toujours actives !
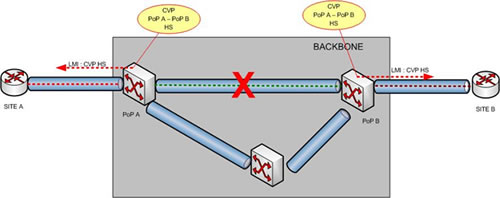
FAUX ! Frame Relay a l’heureuse idée d’embarquer avec lui le protocole LMI (Local Management Interface). Celui-ci va se charger d’informer tous les éléments de la connexion (du CVP) de l’indisponibilité du tronçon PoP A – PoP B. Ainsi les routeurs A et B recevront une information selon laquelle la connexion Frame Relay est hors service. Ils pourront donc engager d’éventuelles procédures de secours …
Remarque : A noter que LMI permet donc également au routeur A d’être informé si la liaison d’accès au site B est HS. En effet, le tronçon Frame Relay PoP B – Site B étant HS tous les éléments du CVP sont informés. Ceci est vraiment très pratique … Vous allez comprendre pourquoi en étudiant ci-après la même problématique pour un réseau IP.
Backbone IP
Dans le cas d’un backbone IP (ou MPLS), c’est un peu plus compliqué … Sur le schéma ci-dessous nous avons toujours nos deux sites connectés au backbone, mais celui-ci n’est plus composé de commutateur Frame Relay mais de routeurs IP.
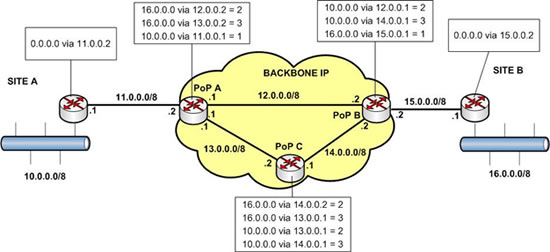
Chaque routeur dispose d’une table de routage indiquant le next-hop pour atteindre chaque réseau IP des sites A et B avec un coût de route correspondant ici au nombre de routeurs à traverser pour atteindre la destination (je sais … c’est du RIP ! Et du RIP sur un backbone c’est à mourir de rire ! Mais c’est pour l’exemple ! Silence !).
Vous remarquerez, que dans cet exemple, les routeurs A et B ont uniquement une route par défaut vers le backbone (0.0.0.0 via 11.0.0.2 pour A par exemple). En effet, celà est très courant chez les opérateurs, car cela simplifie les configurations routeurs. En une seule ligne de routage vous indiquez toutes les directions. Comme ces sites n’ont qu’un seul point de sortie, ce type de routage est largement suffisant ! Bien sûr cette configuration n’a pas été renseignée par RIP mais a été initialisée manuellement par l’administrateur … Malheureusement, cela ne va pas faire nos choux gras comme vous allez le voir ci-après.
Supposons, comme pour le réseau Frame Relay (je dirai FR dorénavant …), que la liaison PoP A – PoP B tombe HS (Hors Service). Que se passe-t-il ?
Le schéma ci-dessous présente la reconfiguration des tables de routage provoquée par RIP. Je vous renvoi au cours « Routage IP» si vous ne comprenez pas cette reconfiguration.
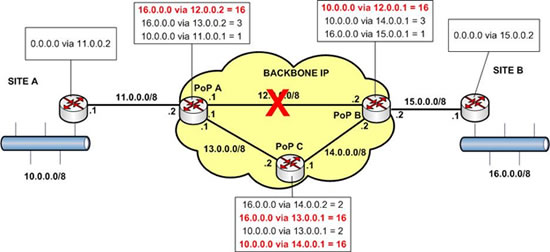
C’est super ! On remarque que les PoP ont reconfiguré leurs tables de routage et qu’ils utilisent la route secondaire via le PoP C. Les routes primaires (en rouge dans le schéma) affichent un coût de 16, elles sont donc HS. Donc la rupture du lien PoP A – PoP B n’a pas eu de conséquence et les sites A et B peuvent continuer d’échanger. C’est quand même mieux qu’en FR non ?
Remarque : Juste pour info … En Frame Relay on peut aussi implémenter des solutions de re-routage backbone en cas d’indisponibilité de segments de CVP. Mais cela se fait par description manuelle est c’est assez lourd. On ne l’implémente généralement que pour des sections « critiques ».
Nous sommes dans un période de malchance … Dans le même temps, le PoP C tombe HS ! Ci-dessous le résultat !
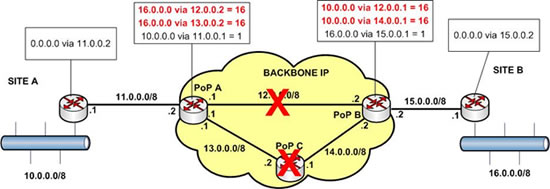
Vous remarquez que le PoP A n’a plus de route vers le site B (réseau 16.0.0.0) et que le PoP B n’a plus de route vers le site A. Cette fois c’est sûr ! Le backbone est bien planté ! Mais les routeurs des sites A et B le savent-ils ?
Non ! Leurs routes par défaut vers leurs PoP respectifs sont toujours actives, car les connexions de niveau 2 vers ces PoP sont toujours fonctionnelles ! Pourtant si les routeurs envoient des paquets IP à leurs PoP ils ne seront pas routés !
Les routeurs A et B devraient donc enclencher une solution de secours, mais ils ne le font pas car ils ne sont pas informés du problème backbone ! Quelle est la solution ?
Il n’y en a pas deux ! Il faut faire participer les routeurs au jeu RIP ! L’utilisation de routes par défaut statiques (saisies manuellement par l’administrateur … pour ceux qui ronflent au fond !) est donc contre indiquée si vous souhaitez mettre en œuvre ici une solution de secours.
Reprenons notre exemple en considérant cette fois que RIP est implémenté sur les routeurs A et B.
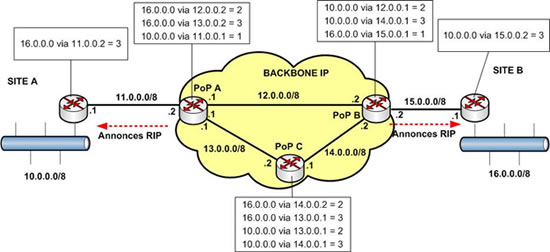
Les routeurs A et B reçoivent des informations de routage en provenance du backbone et dressent leur table de routage en conséquence.
Précision : Je rappelle que le choix de RIP comme protocole de routage backbone est une hérésie ! Je le choisi uniquement parce qu’il est plus facile de comprendre le routage. Dans la réalité on préférera au minimum OSPF voir IS-IS pour un routage backbone !
Maintenant si le lien PoP A – PoP B ainsi que le PoP C sont HS, on obtient :
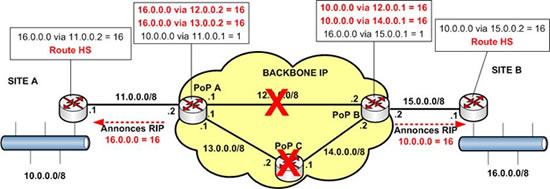
Vous remarquez que cette fois les routeurs A et B reçoivent une annonce RIP leur indiquant l’indisponibilité des routes vers 10.0.0.0 et 16.0.0.0. Ils peuvent donc modifier leurs tables de routage. Ils sont donc maintenant en mesure d’activer une solution de secours …
Détection d’indisponibilité d’un site distant
Nous venons d’étudier la manière dont le site A va pouvoir détecter que son raccordement au réseau est HS ou que le backbone complet et HS. Mais dans certains cas (que nous verrons plus tard), il est parfois également utile que le site soit capable de détecter qu’un site distant (son site central par exemple) est également HS. Pour notre cas, par exemple, il faudrait que le site A détecte si le site B est HS …
Comme dans le cas précédent, tout dépend de la nature du backbone …
Backbone Frame Relay
Nous avons vu précédemment que le protocole LMI permettait d’informer les éléments constitutifs d’un CVP lorsqu’un des segments de ce CVP était HS.
C’est donc très simple, comme l’indique le schéma ci-dessous, nous allons utiliser cette fonctionnalité pour informer A que la liaison d’accès B, ou son routeur sont HS.
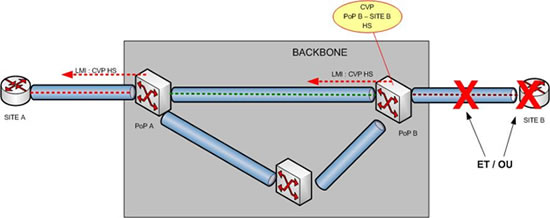
Le site A est donc informé par LMI et peut enclencher son éventuelle solution de secours !
Backbone IP
Comme précédemment, il sera nécessaire qu’un protocole de routage dynamique soit mis en œuvre pour informer le site A que le raccordement au site B est HS.
Le schéma suivant montre la reconfiguration des tables de routage RIP dans cette configuration.
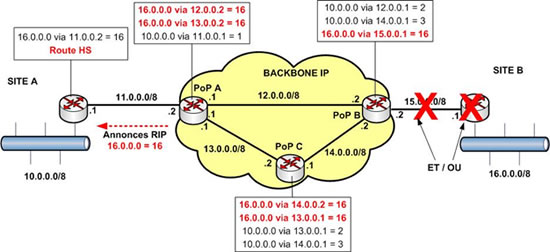
Le PoP B détecte l’indisponibilité du site B par une tombée du niveau 2 du raccordement. Il modifie sa table de routage et passe le réseau 16.0.0.0 en état « inaccessible ». Puis il informe par RIP le reste du réseau. Les annonces RIP remontent jusqu’au routeur du site A qui est ainsi informé. Il peut donc engager une éventuelle procédure de secours !
En synthèse
Nous venons donc d’étudier les différents cas d’indisponibilités possibles ainsi que les méthodes permettant aux routeurs de détecter ses défauts.
Nous avons vu également qu’un backbone IP permettait d’assurer une reconfiguration automatique permettant de le sécuriser. Ainsi il a fallu deux défauts simultanés (dans notre exemple !) pour le rendre inopérant.
Chaque routeur de site a donc maintenant les moyens de savoir qu’il doit passer en mode de secours. A la condition bien sûr qu’une solution de secours ait été prévu. Les chapitres suivants vont donc s’attacher à présenter les différents solutions envisageables !