
Introduction
Nous avons pu remarquer dans les chapitres précédents qu’IP était essentiellement axé sur les fonctions d’adressage et de routage. Il est configuré pour fonctionner comme si aucun problème ne pouvait survenir sur le réseau (perte de datagrammes, congestion, problème de routage, etc.). Si un problème survient, sa solution est expéditive : il ne route pas ! Il a tout juste accepté de prendre en charge les problèmes de fragmentation !
Ce mode de fonctionnement n’est pas un problème en soi (il suffit de regarder la notoriété et l’implantation d’IP !). Mais il est nécessaire de pouvoir dans certains cas informer les émetteurs du devenir de leurs datagrammes.
C’est le rôle d’ICMP (Internet Control Message Protocol) qui, comme son nom l’indique, est un protocole d’information du contrôle de réseau. ICMP ne résoud rien, ou du moins pas grand chose, il informe ! Lorsque certains problèmes de routage se présentent, il émet un message d’information à l’émetteur du datagramme en péril !
Dans 80% des cas, l’émetteur s’en fiche ! Triste monde …
Ce n’est pas tout à fait vrai … La couche IP de l’émetteur s’en fiche ! Mais l’information pourra éventuellement (cela dépend des développements) exploiter ces infos !
ICMP, véhiculé dans IP
Du point de vue d’IP, ICMP est un protocole de couche supérieure presque comme les autres. Les paquets ICMP sont encapsulés dans un datagramme IP. Le champ protocole du paquet IP porte la valeur : (01)h dans ce cas.
La différence réside dans le fait qu’IP pourra, de lui-même, passer une commande à ICMP lorsque certains problèmes se produisent, sans qu’ICMP ait demandé quoique ce soit. Ce n’est jamais le cas avec les autres protocoles de couches supérieures (TCP ou UDP) avec lesquels IP ne discute que pour émettre ou recevoir des données.
Les formats des paquets ICMP varient selon le type d’informations à véhiculer. Nous ne les présenterons pas ici. Il est plus intéressant d’étudier certaines fonctions et certains mécanismes liés à ICMP. Sachez seulement que, dans tous les paquets, il existe un octet d’entête indiquant à quel type de paquet ICMP nous avons à faire. Le tableau suivant liste les principaux paquets ICMP utilisés :
| Hexa | Déc | Message |
|---|---|---|
| 00 |
0 |
Echo response |
|
03 |
3 |
Destinataire inaccessible |
|
04 |
4 |
Source quench |
|
05 |
5 |
Redirection |
|
08 |
8 |
Echo |
|
0B |
11 |
Temps dépassé |
|
0C |
12 |
Problème de paramètre |
|
0D |
13 |
Horloge |
|
0E |
14 |
Horloge response |
|
0F |
15 |
Demande d’information |
|
10 |
16 |
Réponse d’information |
Dans la suite de ce chapitre, nous allons étudier le rôle et quelques applications des paquets « Echo / Echo Response« , « Destination Unreachable« , « Time Out » et « Redirect« . Pour les autres paquets, voici une description rapide :
- Source quench : permet à un équipement de réseau (généralement une passerelle) de signifier à un émetteur une congestion du réseau, afin de solliciter un ralentissement de l’émission. A noter qu’il n’existe aucune primitive permettant de relancer l’émission, l’émetteur temporise l’émission de ses datagrammes tant qu’il reçoit des indications de congestion. Une bonne implémentation d’IP va violemment ralentir son émission à réception des paquets Source Quench, puis reprendre progressivement.
- Problème de paramètre : est émis par un récepteur ou une passerelle à l’émetteur d’un paquet IP dont l’entête comporte une erreur rendant impossible l’exploitation du paquet. Les erreurs de « checksum » ne sont pas traitées car dans de tels cas, l’adresse IP de l’émetteur n’est pas forcément fiable ! Il s’agit en général d’erreurs dans les options. Le paquet ICMP retourné comporte un champ « pointeur » qui indique la partie du datagramme considérée en anomalie. Ce paquet sert très peu, car les options IP sont très peu employées.
- Horloge / Horloge Response : Au départ ICMP avait été conçu pour permettre le calcul des temps de traversée dans le réseau (délais de transit), afin de détecter d’éventuelles baisses de performances. Une autre fonction a ensuite été adjointe, permettant de calculer les différences d’horloge entre les machines émettrices et réceptrices. Ce paquet comporte des champs T1, T2, T3 et T4 permettant de stocker les instants d’émission et réception des paquets aller et retour. Il suffit ensuite d’additionner et soustraire ces champs pour obtenir le délai de transit. Ces paquets sont peu utilisés à ma connaissance. En effet pour être efficace, ce protocole nécessite de synchroniser les bases temps de tous les équipements IP d’un réseau. Cette synchronisation peut être réalisée par un autre protocole nommé NTP (Network Time Protocol). Quoiqu’il en soit, on peut très bien calculer les délais de transit autrement que par ces paquets Horloge/Horloge Réponse, en utilisant le « ping » comme nous le verrons ci-après.
- Demande d’information / Réponse d’information : le seul cas d’utilisation de ces paquets que je connaisse (sans jamais l’avoir vu à l’œuvre !) est la récupération d’adresse réseau. Similaire à RARP (que nous n’avons pas vu, mais qui permet à une station de demander son adresse IP à partir de son adresse MAC), ces paquets permettent à une machine de demander l’adresse réseau sur lequel elle se trouve. Le paquet ICMP_INF_REQ est émis en broadcast et la réponse est fournie par toutes les passerelles du réseau dans des paquets ICMP_INF_RESP. Si vous avez d’autres exemples, n’hésitez pas à m’envoyer un mail !
Echo / Echo Response : Le ping !
C’est quoi ?
Si vous pratiquez IP, vous ne pouvez pas ignorer le fameux PING ! Tous les administrateurs IP, et même les utilisateurs, sont des « pingueurs fous » ! La commande PING issue du monde Unix, permet de tester l’accessibilité d’un équipement IP.
Sur pratiquement toutes les stations IP vous pouvez entrer la commande PING <adresse IP de destination>. Vous recevrez ensuite des informations à l’écran, dont le format varie en fonction des différentes implémentations. Ces informations vous renseignent sur votre capacité à joindre ou non l’adresse visée.
Si vous ne connaissez pas cette fonction, un petit exemple, vaut mieux qu’un grand discours ! Si vous utilisez un PC sous Windows. Cherchez dans le menu Démarrer, la fonction Commande MSDOS (souvent dans les accessoires). Dans la fenêtre (noire !), qui s »affiche entrez : ping 127.0.0.1 (vous pinguez qui là ? … Si vous ne savez pas répondre, vous êtes recalé au partiel !). En réponse vous obtiendrez selon le cas :
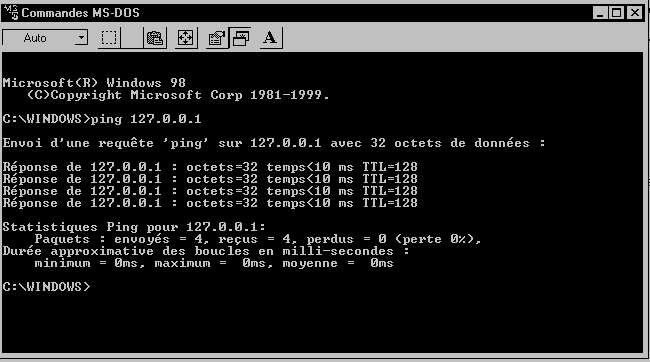
- Request Timout : Pas de chance ! Le serveur ne répond pas ! C’est du moins ce que l’on dit souvent, mais c’est un peu simpliste ! Nous allons y revenir ! Dans notre cas, vous n’obtiendrez ce résultat que si vous n’avez pas de stack IP d’initialisé, ce qui m’étonnerai beaucoup puisque vous êtes connecté à Internet pour lire cette page !
- 127.0.0.1 et des choses derrière … : Le serveur répond ! Vous obtenez également des informations sur le délai d’aller-retour pour atteindre le serveur.
Comment ça marche ?
Lorsque vous entrez la commande PING <@IP>, votre stack IP demande à ICMP d’émettre un paquet Echo vers l’adresse destination :
- l’émetteur formate un paquet ICMP_Echo comportant un numéro d’identification, un numéro de séquence et quelques octets de données aléatoires. Selon les implémentations, vous pouvez modifier les options de nombre d’octets pour visualiser le comportement du réseau sur l’émission de gros paquets. Par exemple, sous Windows vous pouvez modifier la taille par l’option -l.
- le paquet ICMP est placé dans un paquet IP, d’adresse destination égale à celle que vous avez indiqué et d’adresse source égale à celle de l’émetteur.
- lorsque le paquet est émis, votre applicatif « pingueur » enclenche un timer
- puis il émet un nouveau paquet ICMP_Echo du même format que le premier mais ayant un numéro d’identification différent. Il enclenche également à son émission un timer associé au paquet. Il peut répéter cette opération plusieurs fois. Sur Windows de base, le programme émet trois paquets, cependant avec l’option -n vous pouvez modifier ce nombre.
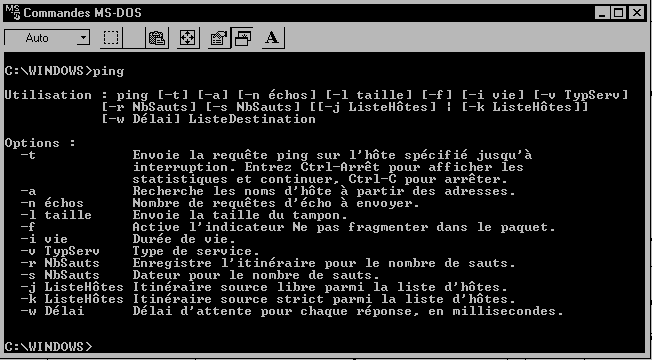
Pour connaître toutes les options du Ping de Windows, entrez simplement « ping » et validez sous les Commandes MSDOS :
Les paquets ICMP_Echo, encapsulés dans des paquets IP, sont véhiculés à travers le réseau jusqu’au destinataire. Quand le récepteur reçoit les paquets ICMP_Echo, il les transfère à son programme ICMP. Celui-va répondre :
- il vérifie le checksum. Si celui-ci est correct, il n’y a pas d’erreur ! (Sans blagues ?). Il passe donc à la séquence suivante, sinon il jette le paquet et ne répond pas.
- il formate un paquet ICMP_Echo_Response ayant les mêmes numéros d’identification et de séquence ainsi que les mêmes données que le paquet Echo auquel il répond. Le numéro d’identification permet de différencier des séquences Echo simultanément lancées depuis la même machine vers le même destinataire (hyper rare !). Le numéro de séquence permet à l’émetteur de repérer quel timer est associé à l’Echo_Response reçu. L’adresse IP source du paquet IP permet de différencier plusieurs émetteurs d’Echo pour un même destinataire.
- le paquet ICMP est ensuite placé dans un paquet IP d’adresse source égale à l’adresse de la station (le récepteur du paquet Echo.. Je précise pour ceux qui aurait du mal à suivre !) et d’adresse destination égale à l’adresse source du paquet Echo précédemment reçu (qui ait l’adresse de l’émetteur du ICMP_Echo… Je précise parce que j’en vois avec des yeux ronds dans le fond à coté du radiateur !).
Le paquet ICMP_Echo_Response, encapsulé dans un paquet IP, est véhiculé à travers le réseau jusqu’au destinataire. Quand celui-ci reçoit le paquet :
- il examine le checksum pour vérifier qu’il n’y a pas eu d’erreur. S’il détecte un erreur, le paquet est détruit, le timer associé est interrompu et vous obtenez une ligne « Request TimeOut ».
- si le checksum est bon, il examine le timer associé : si le timer est arrivé à expiration, le paquet est détruit. Une ligne Request Time Out aura été préalablement retourné immédiatement à expiration du timer.
- si le timer est toujours valide, le programme retourne une ligne vous indiquant la valeur du timer à la réception du paquet. Vous obtenez ainsi le délai de transit aller-retour du paquet.
La même opération est répétée pour tous les paquets.
Certaines implémentations d’IP retournerons une ligne à la fin de l’émission de tous les paquets. Celle-ci indiquera le nombre de paquets perdus (non revenus avant expiration du timer) ainsi que la valeur la plus faible, la plus grande et la moyenne du délai de transit.
La valeur du timer est souvent paramétrable, elle est par contre la même pour tous les paquets d’une même séquence de « ping ». En effet dans certains cas il peut être nécessaire d’adapter ce timer (cas des liaisons satellites par exemple) à la configuration du réseau, sous peine de n’obtenir que des Request TimeOut, les paquets arrivant tous après expiration d’un timer trop court !
A quoi ça sert ?
Nous l’avons déjà dit : Le « ping » sert essentiellement à tester l’accessibilité d’un équipement IP. Si vous avez des réponses positives à un « ping » vous savez que la route « aller » dans le réseau, l’équipement visé et la route « retour » (qui peut être différente de la route « aller » !) sont actifs.
Par contre si vous n’avez pas de réponses vous ne savez pas lequel de ces trois éléments présente un défaut. Dans ce cas, vous allez étudier les tables de routage des passerelles pour déterminer les chemins empruntés et vous allez ensuite « pinguer » chaque élement (passerelle) de la route jusqu’à ce que vous trouviez lequel ne répond pas !
ATTENTION : IP fonctionne en mode non connecté et souvent on implémente dans le réseau des politiques de routage dynamique. Ceci suppose que les passerelles choisissent les routes en fonction de critères qui leurs sont propres. En conséquence, une route « aller » et une route « retour » pour une même destination peuvent être différentes. La recherche d’un élément défaillant dans le réseau (routeur ou lien) par des « ping » peut, dans ce cas, s’avérer trompeuse si on ne maîtrise pas parfaitement le routage. Vous pouvez penser qu’un lien « aller » vers un routeur est hors service, alors que c’est le lien « retour », comme dans l’exemple ci-dessous :
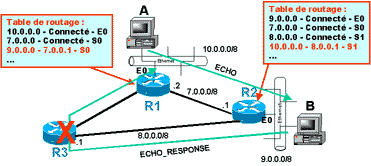
- Le « ping » depuis A vers B ne marche pas !
- Vous « pinguez » R1 sur son interface E0, il répond (normal vous êtes sur le même réseau local !)
- Vous « pinguez » R2 sur son interface E0, il ne répond pas !
- Vous en déduisez que le problème se situe sur le lien entre R1 et R2 ou éventuellement sur R2 !
C’est faux ! En fait, le problème se situe sur le retour R3 ! En effet R2 contacte le réseau 10.0.0.0 via R3 !
Donc … Prudence avec les localisations de défauts par le « ping » !
Autres cas d’utilisation
Le ping peut également être utilisé pour :
- mesurer des délais de transit : Il existe des outils d’administrations qui demandent à des routeurs d’émettre des « ping » et relèvent les résultats de délais de transit pour dresser des tableaux de bords, par exemple.
- mesurer une fiabilité : En émettant des longues séquences de plusieurs centaines ou milliers de paquets consécutifs (attention aux capacités de gestion des timers simultanés), vous pouvez mesurer le nombre de paquets perdus et en déduire une fiabilité ou un taux de perte de paquets.
- simuler une charge réseau pour évaluer l’impact sur les délais de transit et accessoirement en déduire une bande passante bout en bout.
REMARQUES SUR LE DERNIER CAS :
Pour ce type de mesure on préfére souvent FTP, mais dans le cas des nouvelles architectures ATM ce n’est pas toujours le meilleur choix ! En effet :
- vous ne contrôlez pas la taille des paquets émis par FTP, celui-ci ayant tendance à remplir au maximum les segments TCP en fonction de la taille de la MTU locale (celle du LAN sur lequel l’émetteur est placé). Cette taille peut être différente de celle qu’utilise votre application usuelle et dont vous voulez simuler le comportement. Par des « ping » vous pouvez fixer la taille des paquets afin de vous rapprocher de la taille de ceux émis par votre application.
- En ATM, la gestion de la bande passante est dynamique, c’est à dire que vous avez un débit minimum garanti mais vous pouvez le dépasser (on parle de « bursts »). Pour cela vous remplissez plus ou moins de cellules ATM dans le train binaire qui se présente. Par contre si vous dépassez trop longtemps le débit mini, vos cellules sont marquées comme candidates à la suppression (on dit qu’on les « tag »). Si le réseau est surchargé, ces cellules sont supprimées (on dit qu’on les « drop »). Or si une cellule manque, le paquet IP est corrompu (ne parlons pas de la couche AAL5 !), le segment TCP véhiculant le FTP est donc corrompu, et il y a retransmission au niveau TCP ! Mais en ATM les cellules sont toutes petites (48 ou 47 octets utiles selon le cas) et si votre paquet a été coupé en 10 cellules et qu’une seule a été « droppée », vous perdez le tout et il faut tout réémettre ! Votre transfert FTP prend donc plus de temps, donc votre débit utile vous semble plus petit ! En fait, vous avez simplement dépassé votre contrat de trafic et vous avez enclenché les mécanismes de limitations (on appelle ça du « shapping ») ! Si vous faites le même test en TFTP (supporté par UDP, en mode non connecté, sans reprise sur erreur) ou en utilisant le « ping » ICMP il est fort probable que vous mesuriez une bande passante plus conséquente !! Etonnant non ?
Destination inaccessible !
Nous avons vu dans les chapitres précédents, que les maîtres du routage dans un réseau IP, sont les routeurs (ou passerelles). Ceux-ci routent les paquets en se construisant des tables de routage qui dressent la cartographie du réseau. Le routeur est un « bison futé« , il sait à tous moments quelle est la meilleure route pour atteindre une destination !
Mais parfois « bison futé » a des défaillances ! Vous avez tous, un jour de grande affluence, au moment des départs en vacance, suivi un « Itinéraire Vert ». Certes il était vert dans le sens où il vous a amené en pleine campagne ! Mais vous avez ensuite vu rouge quand il vous a largué en plein milieu de « Trou de nulle part » sans aucun panneau pour retrouver son chemin ! Et bien, IP c’est pareil ! Un paquet peut très bien aboutir sur une passerelle qui ignore tout du chemin à emprunter pour atteindre le réseau inscrit en adresse destination !
Mais la passerelle sait reconnaître ses erreurs (ce qui n’est pas le cas de « bison pas futé » !), elle envoie à l’émetteur un paquet ICMP Destination Unreachable !!
L’émetteur est ainsi informé que le paquet n’a pas pu être délivré et que la destination est incontactable. Que fait IP ? … Rien ! S’en fiche ! Selon l’implémentation il pourra éventuellement informer la couche supérieure que son correspondant est parti se coucher ! A elle de décider ce qu’elle veut faire ! TCP va insister grossiérement en relançant ses informations jusqu’à ce qu’il admette enfin que le destinataire est VRAIMENT incontactable. UDP, un peu fainéant ne fera rien !
Le paquet ICMP Destination Unreachable permet d’informer plus précisément l’émetteur sur la cause de la non délivrance du paquet. Un octet de code dans le paquet permet d’indiquer :
Réseau inaccessible (code 0) : si la destination est inaccessible parce que le réseau n’est pas déclaré dans une table de routage d’une des passerelles traversé par le paquet IP
Host inaccessible (code 1) : si la station de destination est incontactable. Le paquet a bien atteint le réseau de destination, mais aucune station n’a répondu à la requête ARP de la passerelle du réseau de destination.
Protocole inaccessible (code 2) : retourné par la station de destination, si le champ Protocole du paquet IP indique un protocole de niveau supérieur non géré par la station. Par exemple si vous envoyez des données IGRP (protocole de routage) à une station qui n’est pas un routeur Cisco !
Port inaccessible (code 3) : retourné par une station qui reçoit un paquet IP, véhiculant un message TCP ou UDP dont le numéro de port destination est inconnu de la station (Là, c’est du niveau 4 ! Laissez tomber …).
Fragmentation nécessaire, mais interdite (code 4) : retourné par une passerelle qui doit fragmenter un paquet, pour pouvoir l’encapsuler dans une trame dont la MTU est inférieure à la taille du paquet, mais qui ne peut le faire car le bit DF (Don’t Fragment) du paquet est positionné à 1 ! Le paquet est jeté, et le paquet ICMP est envoyé à la station. Cette technique est utilisée par TCP lorsqu’il tente de découvrir la taille minimum de la MTU sur une route (j’en ai briévement parler dans le chapitre précédent !). TCP émet d’abord un paquet à la taille de la MTU du réseau local, s’il reçoit un ICMP Destination Unreachable code 4, il diminue la taille et ainsi de suite !
Echec du source routing (code 5) : laissez tomber ! Ce sera trop long ! Sachez que ce message est lié au champ Option du paquet IP qui permet de mettre en place un routage imposé par la source. L’émetteur indique par quelles passerelles doit passer le paquet … Bref ! Assez peu utilisé !
Pas mal ICMP Destination Unreachable ? On en apprend des choses, hein ?
Time Out : Le TTL est mort !
C’est quoi ?
Nous avons vu précédemment que l’entête du paquet IP présentait un champ nommé TTL (Time To Live). Lorsque dans le chapitre précédent nous avons étudié la fragmentation, nous avons évoqué ce champ et la manière dont il était géré par les machines IP. Pour rappel :
- le TTL permet d’indiquer une durée de vie à un paquet IP afin d’éviter que le réseau continue d’acheminer des paquets perdus
- ce TTL est généralement fixé à 255 mais peut être géré par l’émetteur pour diminuer la portée d’un paquet
- un routeur décrémente de 1 le TTL de tous paquets qui le traversent
- lorsqu’un paquet est placé en file d’attente, que ce soit dans un routeur ou dans une station à l’émission ou à la réception, le TTL est décrémenté de 1 toutes les secondes.
- La machine qui passe à 0 le TTL détruit le paquet correspondant.
En conséquence, une station ou un routeur peut avoir à passer le TTL d’un paquet à 0. Celui qui réalise cette opération enverra un paquet ICMP_TIME_OUT à l’émetteur du paquet pour l’informer de sa destruction. Encore une fois, ce n’est pas IP qui réagira, il transmettra l’information aux couches supérieures qui décideront de la conduite à tenir.
L’application au Trace Route
Nous avons précédemment évoqué le « ping » comme une commande très utile pour l’administration d’un réseau IP. Une autre commande très utilisée par les fous d’IP, est le TRACE ROUTE.
Le « trace route », comme son nom l’indique, permet de tracer la route empruntée par un paquet IP pour atteindre sa destination. En lançant cette commande vous recevez en réponse, la liste des passerelles par lesquelles est passé le paquet. Ce programme utilise la gestion du TTL et le mécanisme de l’ICMP_TIME_OUT !
Le principe est le suivant :
- vous entrez sur votre équipement IP la commande trace route <@IPdest>
- le programme Trace route formate un paquet IP d’@IPsource égale à votre station et d’@IPdest égale à celle indiquée dans la ligne de commande. Le TTL du premier paquet est fixé à 1 (au lieu de 255).
- le paquet est émis vers la Gateway Default de votre station pour être routé dans le réseau
- quand le routeur reçoit le paquet il décrémente de 1 le TTL. Il le passe donc à 0, puisqu’il été fixé à 1 !
- le routeur détruit donc le paquet et émet un paquet ICMP_TIME_OUT vers l’émetteur du paquet. Ce paquet est encapsulé dans un paquet IP ayant pour adresse source l’adresse de l’interface de sortie du routeur vers votre station.
- l’émetteur reçoit le paquet ICMP émis dans le paquet IP. Le paquet IP a pour adresse source l’adresse de la passerelle qui a détruit le paquet. Il peut donc vous renvoyez une ligne à l’écran vous indiquant l’adresse de la première passerelle traversée par le paquet.
- puis l’émetteur formate un deuxième paquet IP avec un TTL fixé à 2. Cette fois le premier routeur va passer le TTL à 1 et enverra le paquet au prochain routeur indiqué dans sa table de routage, pour la route concernée par le paquet IP.
- le deuxième routeur passe le TTL à 0 et retourne donc un ICMP_TIME_OUT qui sera reçu par l’émetteur, etc …
- le process est terminée lorsque le paquet atteint la station de destination. En effet dans ce cas, l’adresse source du paquet IP véhiculant le paquet ICMP_TIME_OUT est la même que l’adresse indiquée dans la ligne de commande du « trace route ».
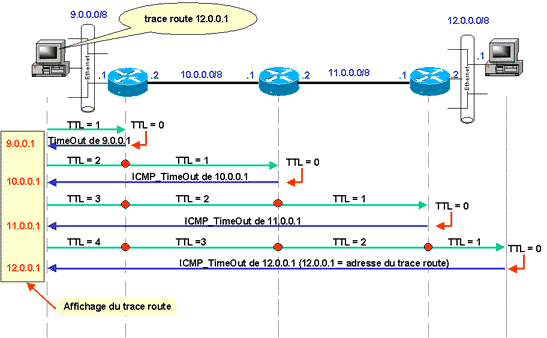
Chaque passerelle de la route empruntée par les paquets IP pour atteindre l’adresse destination, aura donc, au final, transmis un paquet ICMP_TIME_OUT dans un paquet IP ayant pour adresse source l’adresse de l’interface de sortie du routeur. Vous avez ainsi le chemin emprunté !
Quelques petites précisions
Lorsque le programme « trace route » émet un paquet il lui associe un timer (un peu comme dans le ping). Ce timer permet de mesurer le délai aller-retour pour atteindre la passerelle qui placera le TTL à 0. Vous pouvez ainsi obtenir le délai de transit, tronçon par tronçon pour une direction donnée. Le timer permet également de stopper le processus lorsque la route est invalide et que les passerelles ne répondent pas (dans ce cas même un « ping » ne passerai pas, bien sûr !).
La station émettrice peut émettre simultanément des paquets IP de données et des paquets relevant pas du programme trace route pour une même destination. Ces paquets pourrait très bien avoir leur TTL placé à 0 pendant le trajet, pour une raison quelconque. La machine IP qui passerai ce TTL à 0, retournera également un ICMP_TIME_OUT ! Comment l’émetteur peut-il différencier les ICMP_TIME_OUT relevant du process « trace route » des paquets relevant du transfert de données utiles ? En fait, lorsqu’une station formate un ICMP_TIME_OUT elle recopie dans ce paquet l’entête et les 8 premiers octets du paquet IP qu’elle détruit. Il y a donc suffisamment d’information dans ce paquet pour que la station émettrice du paquet détruit puisse identifier le paquet concerné.
Le message ICMP_TIME_OUT permet de différencier deux causes de destruction du paquet par expiration du TTL, grâce à un octet de code :
- Champ TTL épuisé (code 0) : est indiqué lorsqu’une machine IP a reçu le paquet avec un TTL à 1 et a donc dû le placer à 0. On suppose qu’une boucle dans le réseau a fait tourné le paquet trop longtemps.
- Attente trop longue au ré-assemblage (code 1) : est indiqué par une machine qui détruit un paquet IP parce qu’elle n’a pas reçu dans les temps tous les fragments permettant de le reconstituer. Ce code est donc forcément émis par le destinataire du paquet (et pas par une passerelle) puisque seul le destinataire opère le ré-assemblage.
Redirect : Tu te trompes de route !
La Gateway de sortie du LAN
Nous avons étudié au chapitre 5, les bases du routage IP. Dans le paragraphe « Sortir du réseau » nous avons expliqué comment une station contactait sa passerelle de sortie (Gateway Default) pour émettre des paquets en dehors du réseau local.
Mais que se passe-t-il s’il y a plusieurs routeurs sur le LAN, chacun d’eux desservant une ou des destination(s) particulière(s) ?
Peu de stations offrent la possibilité de déclarer une passerelle spécifique pour une route donnée ! A ma connaissance, seules les stations Unix (et sûrement Linux !) permettent de définir une table de routage au sein d’un host IP qui n’est pas une passerelle :
- En environnement Windows 95 vous ne pouvez définir qu’une passerelle par défaut qui sera systématiquement utilisée pour acheminer le trafic sortant du LAN (Merci Bilou ! Tu ne nous simplifie pas la vie, tu sais ?).
- En environnement Windows NT 4 et 5 Workstation vous pouvez définir sur une station plusieurs Gateway Default ! Mais pas pour des routes spécifiques ! Si la passerelle par défaut passe hors service alors qu’elle a déjà été utilisée par la station (la correspondance ARP est mémorisée), il faudra rebooter la station pour pouvoir utiliser la deuxième Gateway (Franchement Bilou ! A quoi tu penses ? ).
- En environnement NT 4 et 5 Server (peut-être NT 3 aussi !), vous pouvez définir une table de routage dans le serveur (Enfin Bilou ! Il était temps de te réveiller !).
Le problème
Donc, comme dans le schéma suivant, supposons que A veuille émettre un paquet à B. A a pour Gateway Default R1, qui malheureusement ne peut pas desservir le réseau de B (pas de chance !).
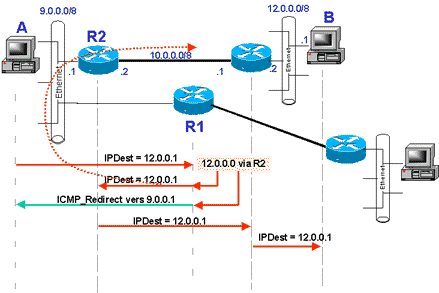
Mais R1 n’est pas totalement stupide ! Dans sa table de routage il voit bien que B peut être atteint en passant par R2 (enfin, si votre plan de routage est bien fait !) ! Quand R1 recevra le paquet à destination de B, il va donc le transmettre à R2 !
Mais R1 n’aime pas travailler pour rien ! Il a bien remarqué, qu’il a été obligé de réémettre le paquet par l’interface sur laquelle il l’a reçu ! Il se dit donc, bien légitimement, que si A été un peu moins stupide il aurait envoyé son paquet directement à R2 !
La solution
Heureusement R1 (bonne âme !) va tenter d’instruire A en lui émettant un paquet ICMP_Redirect, lui donnant l’adresse de Gateway à contacter pour émettre vers le réseau de B !
A va mettre à jour sa table de routage ! Au prochain paquet à émettre vers le réseau de B, il lancera une séquence ARP pour connaître l’adresse MAC de R2, puis lui enverra le paquet !
Super non ? … Pas tant que ça ! Réfléchissons !
L’impact négatif
Nous venons d’admettre que l’ICMP_Redirect a pour effet de mettre à jour la table de routage de l’émetteur ! Mais nous avons aussi dit que peu de stations gèrent une table de routage (les serveurs NT et les serveurs et stations Unix !). Autrement dit, seul ce type d’équipement IP (en dehors des passerelles bien sûr !), exploiterons l’ICMP_Redirect ! Toutes les autres stations vont continuer (bêtement !) d’émettre leur paquet à la Gateway Default !
Dans cette configuration, à chaque fois la passerelle va donc émettre un ICMP_Redirect, après avoir émis le paquet à la bonne passerelle ! Donc au total trois paquets sont émis sur le LAN alors qu’il ne devrait y en avoir qu’un !! (Le LAN est super content ! Cela occupe sa bande passante, qui justement s’ennuyait !!). Bien sûr ce fonctionnement a un impact sur les délais de transit puisque le paquet traverse un routeur de trop (R1) et deux fois le LAN au lieu d’une fois !
Dans un cas d’exploitation réel, j’ai l’exemple d’un client qui a gagné 20% sur ses délais de transit en modifiant la Gateway de ses serveurs. A priori la fonction ICMP_Redirect n’était pas active sur ses routeurs, ou plutôt son serveur n’interprétait pas les paquets ICMP_Redirect !
Une solution pour résoudre le problème
Il n’y a pas beaucoup de solutions pour améliorer ce fonctionnement. Le problème est qu’un routeur est obligé de réémettre un paquet sur le LAN par lequel il l’a reçu !
Si vous désactivez l’ICMP_Redirect sur vos routeurs, vous n’aurez plus de paquets ICMP sur le LAN mais vous aurez toujours le rebond entre routeurs par le même LAN !
La seule solution est donc d’interconnecter les routeurs entre-eux (on appelle ça une liaison « back to back » !) et de déclarer l’un des routeurs (disons, R1 ?) en Gateway Default ! Dans le schéma suivant, comme précédemment, A envoie son paquet pour B à R1, R1 le renvoi à R2 par le lien R1-R2 et non pas par le LAN ! Donc plus d’ICMP_Redirect et plus de double charge du LAN !
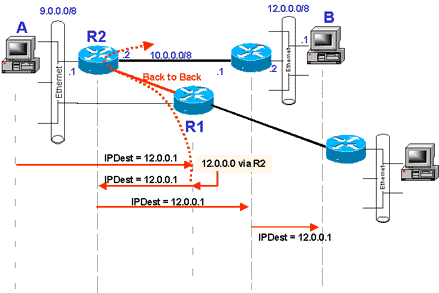
Le problème est où cette fois ? … Qu’arrive-t-il si R1 est HS ? Plus personne ne sort du réseau quelque soit la destination demandée ! Mais on ne peut pas tout voir dans ce cours ! J’ai aussi le droit de garder quelques petits trucs pour les prochains ! Rassurez-vous, il y a des solutions ! Mais ce sera pour un cours sur le routage !
Quelques petites précisions
Comme pour le paquet ICMP_Destination_Unreachable, le paquet ICMP_Redirect posséde un octet de code qui permet de préciser la nature de la redirection :
-
rediriger pour le réseau demandé (code 0) : le plus courant. Dans notre exemple nous avons dit que R1 retournait à A un Redirect pour le réseau de B (pas pour la station). En effet R1 a bien remarqué, dans sa table de routage, que R2 desservait tout le réseau de B.
-
ne rediriger que pour le host demandé (code 1) : nous n’en avons jamais parlé, mais vous pouvez très bien définir, dans une table de routage, une route spécifique pour une station spécifique, au lieu d’un réseau complet. Cela est parfois employé pour l’accès des stations d’administrations à qui on attribue une route spéciale avec accès par RNIS, par exemple. Donc si B avait eu une route dédiée dans la table de routage de R1, celui aurait retourné un Redirect code 1.
-
ne rediriger que pour le réseau et le TOS demandés (code 2) : nous avons peu évoqué le TOS (Type Of Service) qui est encore très peu utilisé. Ce champ, placé dans l’entête IP, permet d’indiquer une priorité à un paquet. Certains protocoles de routage, comme OSPF, permettent de dresser des tables de routage différentes en fonction des TOS. Autrement dit, les routes de deux paquets IP pour un même destinataire, mais ayant des champs TOS différents, peuvent être différentes ! Le Redirect permet de tenir compte de cette particularité en indiquant que la redirection est uniquement valable pour les paquets ayant un TOS et une destination identique.
-
ne rediriger que pour le host et le TOS demandés (code 3) : vous avez bien compris que code 3 = code 1 mais en ajoutant le critère du TOS !
Afin que la station émettrice identifie le paquet pour lequel elle reçoit un ICMP_Redirect, le routeur recopie dans l’ICMP l’entête IP et les 8 premiers octets de données du paquet qu’il place en redirection. Ainsi la station émettrice peut notamment retrouver l’adresse IP de destination en cause !
Conclusion du chapitre
Et voilà ! Nous en avons terminé avec cette présentation sommaire des principales fonctions d’ICMP. J’ai tenu à illustrer certaines d’entre-elles par des cas réels d’utilisation car il n’est pas toujours évident d’en comprendre l’utilité !!
Il reste un grand flou sur la manière dont les stations émettrices exploitent les informations transmises par ICMP. Les programmes « ping » et « trace route » sont clairs, mais restent des programmes essentiellement dédiés à l’administration. Un « ping » ou un « trace route » n’a pas de réelle valeur sur un transfert de données utiles. Ce que fait une station lorsqu’elle reçoit un ICMP Source Quench, un ICMP Time_Out, ou un quelconque autre ICMP, dépendra :
- de l’implémentation IP mise en oeuvre dans le stack installé sur la machine (existe-t-il des primitives pour remonter les informations aux couches supérieures ?)
- de l’implémentation des couches TCP et UDP du stack installé (si des primitives ICMP remontent d’IP, TCP et UDP en tiennent-ils compte ?)
- de l’implémentation des applications de couches supérieures (si TCP ou UDP retournent des informations issues des primitives ICMP, les applications les exploitent-elles ?).
J’avoue manquer d’informations sur le sujet !
IP se termine avec ce chapitre ! Il y a sans aucun doute beaucoup de choses à dire encore, mais l’essentiel a été présenté ! Le reste viendra avec l’expérience ! Sur les prochains cours, je pense m’attacher plus aux principes de routages IP, qui est un sujet véritablement passionnant !
Le chapitre suivant vous propose trois organigrammes pour résumer le contenu de ce cours !
Page Précédente | Page Suivante