
Qu’est-ce qu’un plan d’adressage ?
Lorsque vous devez créer un réseau d’entreprise IP, ce réseau interconnectant différents sites et réseaux de votre société, vous réfléchissez à un plan d’adressage. Cette opération a pour but de définir pour chaque réseau physique (LAN et WAN) une adresse de réseau IP. Pour chaque machine de chacun de ces réseaux, vous devrez choisir une adresse machine dans le réseau IP choisi.
Pour définir la ou les classes d’adresses que vous allez choisir, vous tiendrez compte du nombre de réseau physique de votre réseau d’entreprise et du nombre de machines sur chacun de ces réseaux. Vous avez alors différentes possibilités :
- vous choisissez des adresses réseaux IP totalement librement (1.0.0.0, 2.0.0.0, 3.0.0.0, etc.). Vous définissez ainsi un plan d’adressage privé, mais vous ne vous assurez pas de l’unicité mondiale des adresses. Autrement dit, si vous envisagez un jour de connecter votre réseau à Internet, il y a de fortes chances que ces adresses soient déjà attribuées à d’autres sociétés. Vous aurez alors de sérieux problèmes de routage vers Internet et vous serez obligé de rectifier le tir de deux façons possibles :
- sur votre point de sortie vers Internet vous placez un équipement (routeur ou FireWall) qui va modifier « à la volée » vos adresses de machines pour les rendre compatibles avec le plan d’adressage Internet. Cette fonction de translation d’adresse est appelée NAT : Network Adress Translation.
- vous redéfinissez complétement votre plan d’adressage avant d’être viré par votre PDG !
- vous prévoyez votre interconnexion possible avec Internet et, à ce titre, souhaitez être compatible avec son plan d’adressage. Vous définissez un plan d’adressage conforme au plan d’adressage public. Pour cela, vous demandez à des organismes spécifiques (NIC, AFNIC ou votre IAP : Internet Access Provider) des adresses IP publiques qui vous seront réservées. Avec ces adresses réseaux vous définirez votre plan d’adressage interne. Le problème de cette solution est qu’il y a une très grosse pénurie d’adresses IP publiques ! C’est d’ailleurs une des raisons qui a conduit à redéfinir une nouvelle version du protocole IP, l’IP V6, qui propose un format d’adressage sur 16 octets ! Vous aurez donc très peu d’adresses, et si votre réseau est important vous risquez d’être coincé !
- la dernière solution est d’utiliser des adresses dites non « routables ». Ce sont des adresses réseaux spécifiques qui ne sont et ne seront jamais utilisées sur Internet. Vous êtes ainsi sûr de ne pas avoir de conflit d’adressage. Ces adresses sont définies par une RFC spécifique, la RFC 1918.
L’objectif de ce chapitre est donc de vous présenter ces quelques concepts de définition des plans d’adressage.
Problématique de l’interconnexion avec Internet
IP a été conçu pour interconnecter des réseaux au niveau mondial. Il est notamment implémenté sur Internet. On peut concevoir facilement qu’il est impératif que deux serveurs ou deux réseaux d’entreprises raccordés à Internet n’est pas la même adresse. Sinon, il y aura un conflit de routage (vous aimeriez que votre voisin reçoive votre courrier ?).
Chaque I.A.P (Internet Access Provider : Orange, WORDLCOM, C&W, etc.) dispose d’un « pool » d’adresses IP (réseau et à fortiori donc machine !) qu’ils peuvent affecter à des clients qui leur demande un accès Internet. Ces adresses sont attribuées par des organismes très sérieux qui veillent à la cohérence du plan d’adressage Internet : unicité des adresses, répartition géographique des « pools » contigus (le fameux CIDR pour les érudits !). Ces organismes s’appellent le NIC (Network Information Center), l’AFNIC, etc. On les appelle des « registrar« .
Cependant le plan d’adressage IP, même s’il est copieux, n’autorise pas un nombre infini d’adresses réseaux ou machines. En conséquence, lorsqu’une entreprise veut connecter son réseau à Internet, elle n’obtient pas autant d’adresses qu’elle le souhaiterai. En effet, il y a actuellement une pénurie d’adresses publiques, notamment en classe A et B. Ces deux classes sont les plus recherchées car elles offrent de plus grandes possibilités en nombre de machines et, vous le verrez plus tard, en définitions de sous-réseaux. Cette pénurie a conduit, pour partie, à la définition d’une nouvelle version d’IP, l’IP V6, qui offre, notamment, un adressage sur 16 octets (Demain, toutes les cafetières du monde pourront avoir leur adresse IP !!).
Revenons à notre entreprise qui réclame des adresses publiques pour créer son plan d’adressage interne. Lorsqu’elle fera la demande d’adresses, il faudra qu’elle justifie de son besoin. Et sachez que l’argument « Je veux donner une adresse publique à tous mes utilisateurs » est un MAUVAIS argument ! On lui répondra « Et la NAT vous connaissez ? » et on ajoutera « Et la RFC 1918 vous connaissez ? », pour finir on lui dira « Si vous ne connaissez pas, allez lire le cours IP à l’adresse http://www.gatoux.com/ et revenez nous voir quand vous aurez compris ! ». Finalement on lui donnera, généreusement, 8 adresses machines et débrouille-toi !
N.A.T sauve moi !
N.A.T pour Network Address Translation (rien à voir avec le diminutif de Nathalie !) permet de « translater » une adresse IP en une autre. Plus fort ! Il existe deux formes de NAT :
- le « natage » (mon dieu quelle horreur !! Promis je le ferai plus !), la translation d’adresse source qui consiste à modifier l’adresse source d’un paquet IP en une autre adresse. Par cette technique on dit souvent que l’on masque le plan d’adressage interne. En effet, tout paquet qui franchi l’équipement effectuant la NAT (routeur, FireWall ou Proxy) part avec une adresse source différente de la vraie adresse source de l’émetteur. Un observateur extérieur (pour ne pas l’appeler un « hacker » ou « pirate » !!) ne verra donc qu’une adresse affectée par translation ne correspondant pas à une réelle adresse de l’émetteur. Généralement l’adresse affectée est celle de l’interface de sortie de l’équipement qui assure la translation.
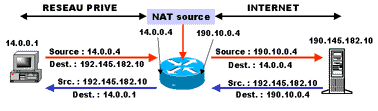
- la translation d’adresse destination, moins courante, permet de modifier l’adresse destination d’un paquet IP lorsque celui-ci demande une adresse spécifique. Vous pouvez, de cette manière, masquer l’adresse réelle d’un serveur au monde extérieur ! Les internautes cherchent, par exemple, à contacter l’adresse 132.12.12.11 qui correspond en fait à votre adresse de FireWall (Pare-Feu). Le FireWall à réception des paquets va modifier l’adresse en 10.0.0.1 qui est l’adresse interne de votre serveur ! De cette façon on ne peut pas joindre votre serveur sans passer par votre FireWall ! Bien sûr, lors de la réponse du serveur, le FireWall modifiera l’adresse source de réponse !
La N.A.T permet de n’utiliser qu’une seule adresse machine coté Internet. Cette adresse est affectée à l’interface de sortie de l’équipement réalisant la NAT. Tous les paquets, de tous les utilisateurs internes, partiront sur Internet avec cette adresse source. Mais bien sûr les réponses des serveurs sur Internet se feront toutes vers l’adresse source indiquée dans le paquet qu’ils reçoivent, c’est à dire celle de l’équipement qui assure la N.A.T !
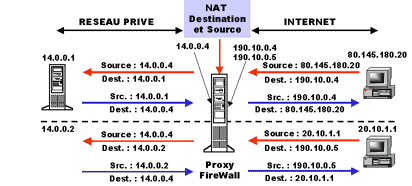
Dans ce cas, comment faire pour que les réponses arrivent bien à chaque machine qui a émis initialement la requête ? C’est assez simple … L’équipement N.A.T va maintenir une table de correspondance des translations en cours !
Lorsqu’une station envoie un paquet IP vers l’extérieur, il mémorise l’adresse source interne de la station et l’adresse destination externe demandée. Ce couple est insuffisant car lors des réponses l’équipement disposera toujours de la même adresse destination (la sienne !), il ne peut donc pas déterminer à qui il doit réémettre le paquet. De la même manière, s’il se base sur l’adresse source du paquet, il pourra retrouver la correspondance d’adresse de la station initiale mais seulement si une seule station discute avec le serveur ! Si plusieurs stations discutent avec le même serveur externe il ne peut pas savoir à laquelle retransmettre le paquet. Il doit donc mémoriser des informations supplémentaires pour identifier de manière unique un couple station_interne – serveur_externe de manière unique.
Il mémorise donc également les ports source et destination du segment TCP ou UDP véhiculé par le paquet IP. Pour une machine IP donnée le couple @IP-N° Port Source est toujours unique ! Le sujet du cours n’étant ni TCP/UDP ni la N.A.T nous ne pousserons pas plus loin ! Croyez-moi sur parole si vous n’avez rien compris à la démonstration précédente.
L’équipement de NAT mémorise donc la correspondance :
adresse source interne – port tcp source – adresse destination demandée – port tcp destination.
Au retour des paquets il examinera les couples adresses sources, ports TCP (destination et source) et pourra retrouver l’adresse destination à donné au paquet pour qu’il soit routé en interne !! Compris ?
Tout cela pour vous faire comprendre que rien n’oblige une entreprise à mettre en place un plan d’adressage IP public (avec des adresses attribuées par un « registrar » ou obtenues auprès du NIC directement par l’entreprise). En effet :
- si l’entreprise n’a pas l’attention d’interconnecter son réseau avec Internet, elle n’est pas obligé de respecter son plan d’adressage ! Mais attention si son besoin évolue ! Car refaire un plan d’adressage complet d’un réseau d’entreprise est loin d’être anecdotique ! Vous jouez votre place sur ce coup là !
- même si elle veut interconnecter son réseau avec Internet, nous venons de voir, que l’activation de la NAT sur le routeur d’interconnexion, permettra de masquer le plan d’adressage interne et de se mettre en conformité avec le plan d’adressage Internet.
Donc la NAT c’est la solution à tous vos soucis ? Presque … Attention, le loup veille dans le bois …
Un loup bien caché !
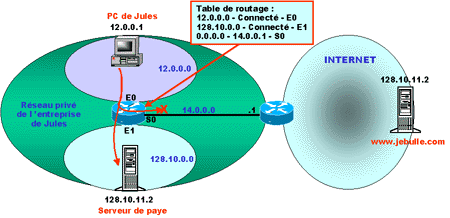 Imaginons qu’une entreprise mettent en place un réseau IP interne sans respecter le plan d’adressage Internet. Elle souhaite, tout de même, s’interconnecter avec Internet, mais pense que la NAT sur le routeur d’accès résoudra tous les problèmes … C’est faux !
Imaginons qu’une entreprise mettent en place un réseau IP interne sans respecter le plan d’adressage Internet. Elle souhaite, tout de même, s’interconnecter avec Internet, mais pense que la NAT sur le routeur d’accès résoudra tous les problèmes … C’est faux !
Supposons qu’elle crée un réseau 128.10.0.0 sur lequel elle installe son serveur d’application (la paye par exemple ! C’est beau un serveur de paye, non ?), ayant pour adresse 128.10.11.2 ! Maintenant supposons qu’un utilisateur, Jules (toujours lui !), du réseau veuille surfer sur Internet et notamment atteindre le serveur www.jebulle.com ! Après résolution DNS (désolé, mais DNS ce sera pour un autre jour !) le PC de Jules est informé que le serveur en question est à l’adresse : 128.10.11.2 !! Vous sentez le problème ? C’est l’adresse du serveur de paye ! A votre avis ? Jules atteindra-t-il le serveur www.jebulle.com ? Suspense ….
Et bien, non !! Il ira sur le serveur de paye !! Et pourquoi ? Parce que les routeurs internes au réseau de l’entreprise qui interconnectent les différents réseaux locaux (LAN : Ethernet, Token Ring, etc…) connaissent un réseau interne 128.10.0.0 et envoient le trafic vers ce réseau …
En fait, dans tous les réseaux d’entreprises, lorsqu’ils sont interconnectés à Internet, on applique la méthode du routage par défaut vers Internet. Cela veut dire que quand un routeur interne ne connaît pas précisément une adresse réseau demandée en destination, il va envoyer le paquet sur une route par défaut (0.0.0.0 : vous vous souvenez ?), qui généralement correspondra au routeur de sortie, d’interconnexion avec Internet. Le routeur de sortie vers Internet aura les moyens d’acheminer ce paquet vers www.jebulle.com (là, je vous passe les détails … Il faut bien s’arrêter quelque part !), et pourra également appliquer la NAT si vous le désirez. Mais encore faut-il l’atteindre !
Donc si on veut enclencher le routage par défaut au niveau des routeurs internes, il faut que les adresses de serveurs Internet ne puissent jamais correspondre à des adresses de serveurs internes à l’entreprise ! Pour être plus précis, étant donné que les routeurs ne connaissent que des adresses réseaux et pas machines, il faut que l’adresse réseau du service demandé sur Internet, ne corresponde jamais à une adresse réseau interne à l’entreprise !
En conséquence, si vous n’avez pas cherché à être en conformité avec le plan d’adressage Internet en pensant que la NAT vous sortira de toutes les situations, c’est perdu ! Vous courrez à la catastrophe, NAT ou pas NAT !
D’accord mais on vous a dit que le plan d’adressage IP public est saturé ! On vous a dit que vous n’obtiendrai jamais assez d’adresse IP normalisée pour adresser tous vos réseaux internes ! Comment faire ?
RFC 1918, sauve moi !
La RFC 1918 vient à votre secours ! Cette RFC défini un « pool » d’adresse IP réseaux dites « non routables ». C’est à dire, que le NIC (et l’IETF) garanti qu’aucun serveur sur Internet n’utilisera ces adresses réseaux ! On appelle également ces adresses des adresses IP privées.
Si un petit génie vous pose la question suivante (Je sais ! Moi-même, je la pose souvent ! Suis-je donc un génie ?) :
- Etes-vous conforme à la RFC 1918 ?
Ne le regardez plus avec des yeux ronds ! Si vos adresses IP internes sont conformes à celles que je présente ci-dessous, vous pouvez répondre « Oui », sinon …
Liste des adresses réseaux non routables :
- toutes les adresses du réseau 10.0.0.0 (Classe A)
- toutes les adresses des réseaux 172.16.0.0 à 172.31.0.0 (Classe B)
- toutes les adresses du réseau 192.168.0.0 à 192.168.255.0 (Classe C)
Si votre plan d’adressage interne est établi sur ces adresses, vous n’aurez aucun problème de routage par défaut vers Internet. Utilisez ces adresses et faites de la NAT pour sortir sur Internet avec les quelques adresses normalisées que votre IAP vous aura généreusement attribué !
Mais ces quelques adresses « privées » RFC 1918 suffiront-elles à adresser l’ensemble de vos réseaux et machines ? Probablement que oui … Mais vous avez aussi la ressource des sous-réseaux pour définir plus de réseaux ! Nous y arrivons enfin !
Qu’est-ce qu’un sous-réseau ?
Les sous-réseaux sont des sous-répartitions d’un réseau. Nous savons :
- qu’une adresse IP est formée d’une partie réseau et d’une partie machine
- qu’on affecte une adresse réseau à chaque réseau physique
Si chaque réseau physique comporte moins de stations que ne peut en définir la partie machine de l’adresse réseau affectée, on gaspille des adresses !
On va dans ce cas utiliser une partie des bits machines de la partie machine de l’adresse pour étendre la partie réseau de l’adresse. En ajoutant ces bits à la partie réseau on se donne plus de possibilités d’adresses réseaux. Cependant on sort dans ce cas du cadre normalisé des Classes A, B ou C ! La partie ajoutée est donc considérée comme une sous-répartition de l’adresse réseau dans sa classe initiale. C’est le sous-réseau !
Utilité des sous-réseaux
Les sous-réseaux ont essentiellement deux cadres d’utilisation :
- permettre de « tronçonner » une plage d’adresse normalisée (conforme à Internet) trop juste pour affecter une adresse réseaux par réseau physique de l’entreprise.
- permettre dans les grands réseaux, une optimisation du routage, en diminuant le nombre de réseaux déclarés dans les tables de routage des passerelles.
Cas du « tronçonnage » !
Si une entreprise désire créer un réseau interne complet, sur un plan d’adressage dit « public » (en cohérence avec celui d’internet), nous savons maintenant qu’elle ne disposera pas d’une infinité d’adresses réseaux. Il faudra qu’elle ruse pour définir chacun de ses réseaux physiques (Ethernet, Token Ring, Liaisons Louées) avec une seule adresse réseau (voir avec une partie d’adresse réseau) fourni par son IAP !
Dans ce cas, elle va tronçonner son adresse réseau en sous-réseaux pour définir un sous-réseau par réseau local (LAN) par exemple. Bien sûr cette technique limitera le nombre de machines qu’elle pourra installer sur chaque réseau physique, mais bien souvent ce n’est pas un problème.
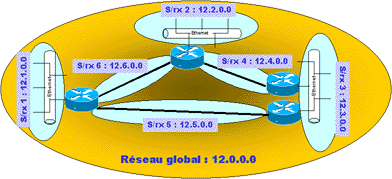
Cas de l’optimisation du routage !
A votre avis ? L’optimisation du routage c’est quoi ? Ci-dessous, le schéma d’un réseau privé faisant appel à un plan d’adressage standard de classe A. Chaque routeur connaît l’ensemble des réseaux :
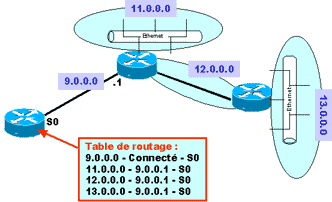
Supposons qu’un réseau soit « subnetter » (humm.. Joli mot !) en 10 sous-réseaux. Si le routeur connaît les dix sous-réseaux il aura dix lignes dans sa table de routage (rappelez-vous le chapitre précédent).
Mais nous savons maintenant que les sous-réseaux font partie d’une même adresse réseau. Donc si on localise dans un même endroit du réseau l’ensemble des sous-réseaux d’un réseau, les routeurs à l’extérieur de cette concentration pourront considérer l’ensemble de ces sous-réseaux comme un seul réseau. Le schéma suivant propose de remplacer les réseaux 11.0.0.0, 12.0.0.0 et 13.0.0.0 par des sous-réseaux d’un réseau 11.0.0.0. Le routeur externe n’a plus que deux lignes dans sa table de routage. Il identifie le réseau 11.0.0.0 dans sa globalité, charge au routeur interne de traiter la séparation en sous-réseaux.
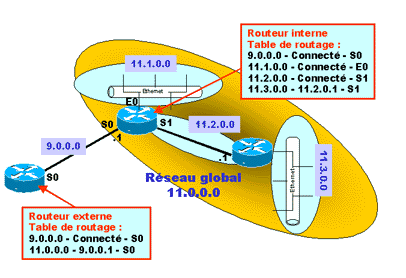
Si un routeur externe à cette concentration envoie un paquet au routeur interne à la concentration il atteindra forcément le sous-réseau, le routeur de la concentration se chargeant de router vers les bons sous-réseaux. Il suffit alors d’avoir une seule entrée dans la table de routage du routeur externe, celle du réseau, le routeur interne aura lui une entrée pour chaque sous-réseaux.
Avec une telle structure d’adressage, vous hiérarchisez votre routage et allégez vos tables de routage. Un routeur n’aime pas les grosses tables de routage, moins il a d’entrée dans la table, moins il a de lignes à scruter, plus il commute rapidement et moins de mémoire il lui faut !
Bien sûr il faudra bien qu’à un endroit, un routeur ait connaissance des sous-réseaux (le routeur de concentration) pour faire la séparation du trafic, mais plus ce routeur est prêt de la destination moins les autres ont à connaître de routes.
Pour la petite histoire, ce concept est tellement important dans les grands réseaux et notamment pour Internet qui route des millions de réseaux, qu’un protocole appliquant ce principe au niveau des adresses réseaux consécutives a été produit. Ce protocole s’appelle le CIDR (Classless InterDomain Routing). Ce protocole permet de regrouper sur le plan du routage des adresses réseaux consécutives 1.0.0.0, 2.0.0.0, 3.0.0.0 etc. en considérant une seule route pour le groupe. On raméne donc à une entrée de table de routage au lieu des 3 de notre exemple. Il faut bien sûr que ces réseaux soient regroupés « géographiquement ». C’est d’ailleurs la logique qui essaie (j’ai bien dit essaie !) d’être respectée sur Internet avec des blocs consécutifs pour la plaque Europe, pour la plaque Asie, etc.
Conclusion du chapitre
Alors, à votre avis ? L’architecture réseau c’est facile ? Rassurez-vous on s’y fait très vite. Mais ce chapitre avait pour but d’introduire quelques éléments de base et fondamentaux pour construire un bon plan d’adressage. Je l’ai réécris plusieurs fois pour essayer d’être à la fois le plus simple et le plus logique possible. J’espère avoir réussi ! Il était difficile, à mon sens, d’introduire la notion des sous-réseaux sans passer par les bases d’un plan d’adressage.
Vous avez maintenant des notions de routage, des notions d’adressage avec des standards comme la NAT ou la RFC 1918. Il vous manque un dernier point pour conclure ces chapitres sur l’adressage IP :
- comment créer des sous-réseaux
- comment identifier un sous-réseau
C’est l’objectif du chapitre suivant … Accrochez-vous à votre calculette ou à votre boite d’aspirine selon le cas ! Et bon courage !