
Dans le chapitre précédent, vous avez pu assister à une mise à mort de RIP ! Même si j’ai relativisé mon discours en conclusion, il n’en reste pas moins que RIP, et les protocoles à vecteurs de distance en général présentent des contraintes parfois pénalisantes. Les réseaux d’entreprises d’aujourd’hui deviennent de plus en plus vastes et de plus en plus complexes. Souvent ils ne peuvent plus se contenter du mode de fonctionnement des protocoles à vecteurs de distances.
Aussi, l’IETF s’est mis à plancher en … sur un protocole de routage ayant une approche radicalement différente. Ces travaux ont donné naissance au routage par « états de liens ». La différence entre « vecteurs de distances » et « états de liens » a été largement expliquée dans le chapitre 4.
Nous allons ici aborder (très légèrement !) un exemple de protocoles à états de liens : OSPF.
Que reproche-t-on aux protocoles à « vecteurs de distances » ?
Les principaux reproches que l’on peut faire aux protocoles à vecteurs de distances sont les suivants :
- une latence importante : en effet nous avons vu que l’algorithme de traitement des informations de routage induisait un délai de mise à jour des tables très importants dans le cas de réseaux de grande taille.
- une utilisation de la bande passante importante : nous avons vu que chaque routeur émettait la quasi-totalité de sa table de routage sur toutes ses interfaces en broadcast, à des intervalles de temps donnés (les hello-times). Ceci induisait une utilisation moyenne constante de la bande passante du réseau, au détriment des vrais, bonnes données !
- des notions de coûts simplistes (nombre de sauts pour RIP) qui avaient pour conséquence de limiter la taille des routes possibles et d’interdire l’optimisation du routage. RIP préfère ainsi une route composée de 2 routeurs séparés par une liaison à 64 Kbps à une route de 3 routeurs séparés par deux liaisons 34 Mbps ! Pourtant la seconde route est sans contexte, la plus rapide et la moins sujette à la congestion !
Certains protocoles comme IGRP ou e-IGRP ont permis d’améliorer ces fonctionnements en implémentant des notions de coûts plus complexes, des capacités d’émission d’updates sur changement d’état de liens ou encore une sectorisation du réseau en pseudo-aire (les groupes IGRP), mais l’algorithme de traitement de base reste le « vecteur de distance » avec sa vue du réseau limitée à la périphérie de chaque routeur (voir le chapitre 4). Pour ces deux protocoles, l’inconvénient majeur reste également qu’ils sont purement Cisco (brevets déposés). Même si Cisco est très présent sur le marché des routeurs, on trouve un tas d’autres constructeurs !
Bref ! Il était temps de chercher autre chose !
OSPF : principaux apports …
OSPF (Open Short Path First) est un protocole à états de liens, à ce titre son approche du routage est radicalement différente de celle de RIP et autres protocoles dits « à vecteurs de distances ». Référez-vous au chapitre 4 pour en comprendre la différence. Résumons ici les principales caractéristiques d’OSPF :
- C’est un protocole ouvert (non propriétaire) et standardisé par la RFC 1247. Il est le fruit d’un groupe de travail de l’IETF auquel a d’ailleurs largement contribué DIGITAL.
- Il autorise le routage par type de service (champ TOS du datagramme IP).
- Il assure automatiquement un équilibrage de charge (load balancing), si plusieurs routes de même coût sont définies vers un même réseau pour un même TOS.
- Il permet de diviser le réseau en zones, toutes autonomes, et invisibles pour les zones voisines. OSPF implémente une notion d’aires. Vous divisez votre réseau en plusieurs zones correspondants à des aires (par exemple, l’aire Sud-Ouest, l’aire Nord-Est, etc…). Les aires sont interconnectées entre-elles par une aire spécifique appelée « l’aire backbone ». Ceci permet d’optimiser le routage en annonçant des résumés de routes. Cette hiérarchisation va plus loin en permettant d’indiquer des natures de réseaux IP différentes, selon que le réseau supporte un seul routeur ou plusieurs routeurs (notion de stub). Chaque routeur maintient une base de données (la LSDB : Link State DataBase) indiquant la topologie de sa propre zone.
- Il est capable de gérer les routes de machine à machine, les routes vers les réseaux, ainsi que le routage vers les sous-réseaux.
- Les échanges entre routeurs sont authentifiés, ce qui permet de s’affranchir des problèmes de malveillance.
- Sur un réseau à accès multiples, il y a possibilité d’avoir une seule passerelle diffusant les messages d’état de lien (notion de Directory Router et Backup Directory Router) aux autres routeurs, ainsi les média sont moins chargés par des messages de protocole de routage.
- Utilise l’adressage multicast IP. Celui-ci est moins polluant que le broadcast, dans le sens ou seules les machines implémentant OSPF analyse le contenu des paquets IP émis en multicast (aux adresses correspondantes au trafic OSPF).
- Il réagit rapidement aux changements de topologie sans générer trop de trafic. OSPF fonctionne très différemment de RIP. Lorsqu’un lien change d’états (liaison d’interconnexion devenant indisponible ou inversement), OSPF émets des updates (LSA : Link State Advertisement) à tous les routeurs voisins en « multicast IP ». Les updates ne décrivent que le changement d’état du lien et pas l’ensemble de la table de routage du routeur ! Tous les routeurs retransmettent immédiatement ces mises à jours à tous leur voisins également. Tout le réseau est ainsi immédiatement informé du changement d’état d’un lien ! Chaque routeur peut modifier sa table de routage en conséquence.
- Un coût de route plus souple : OSPF autorise le paramétrage des coûts sur les interfaces sortantes. Ceci vous permet donc de tracer vos routes aussi sûrement que si vous aviez mis en place un routage statique, mais en conservant l’intérêt du routage dynamique (la reconfiguration automatique du routage). Par défaut, si vous n’appliquez pas de coût spécifique, le coût d’OSPF est calculé par rapport à la bande passante du support (nous y reviendrons plus tard !).
- Il autorise l’utilisation des masques de sous-réseaux de longueur variable (VLMS : Variable Length Mask Subnet)
Dans les paragraphes suivants nous décrirons plus précisément certains des quelques points mis en avant ici.
Mécanisme d’échange de base …
Tout d’abord, chaque routeur implémentant OSPF se défini un identifiant unique dans le réseau, permettant aux autres routeurs d’identifier la provenance des mises à jour et également les équipements connectés sur les liens décrits dans les updates. Cet identifiant est automatiquement choisi sur le principe de l’adresse IP la plus élevée affectée aux interfaces du routeur. Comme il n’est pas possible d’avoir deux adresses IP identiques au sein d’un même réseau, ce principe garanti que l’ID routeur sera unique.
Puis les routeurs construisent des LSA (Link State Advertising) attribuant à chaque réseau qui leur est directement connecté un coût d’accès. Ce coût peut avoir été affecté manuellement par l’administrateur à la programmation du protocole, ou il peut être calculé automatiquement sur le principe suivant :
coût_interface = 109 / Bande passante du réseau correspondant
Ainsi une interface Ethernet à 10 Mbps aura un coût de 100 (100 = 1 000 000 000 / 10 000 000)alors qu’une interface sur un lien 1 Mbps aura un coût de 1000.
Ces LSA sont transmis à tous les routeurs voisins par un multicast AllSPF (224.0.0.5). Seules les machines implémentant OSPF examineront le contenu des paquets IP Multicast ayant l’adresse 224.0.0.5. Ceci permet d’éviter que des machines IP standards (serveurs, PC) sur un LAN examinent les paquets IP émis par les routeurs. C’est autant de charge en moins !
Un nouvel LSA est immédiatement émis si une des composantes du précédent a changé. Cet LSA de réajustement ne comportera que le delta par rapport au précédent émis, c’est le « steady-state« . Ceci permet de minimiser les tailles des messages émis (gain en bande passante) et également de permettre une meilleure réactivité du routage.
Les routeurs construisent avec les LSA reçus une LSDB (Link State Data Base) et calculent ainsi un ou plusieurs arbres SPF, ils mémorisent ainsi plusieurs topologies de réseau utilisant les moindres coûts de routage pour chaque destination. Il est ici nécessaire de comprendre que la LSDB n’est pas la table de routage ! C’est une base de données construites alimentée par les LSA dans laquelle le process OSPF puise pour extraire un arbre de routage. Donc :
- Tous les routeurs possèdent la même LSDB (pour le peu qu’ils soient dans la même aire ! Mais bon ! Ne compliquons pas les choses !)
- Chaque routeur calcule un arbre de routage différent, puisque celui-ci dépendra da la position relative du routeur dans le réseau.
Référez-vous au chapitre 4, si cette notion vous semble nébuleuse !
Toutes les 30 minutes il y a resynchronisation des routeurs par une comparaison des LSDB afin de se prémunir d’éventuels « ratés » dans les échanges de LSA.
Comment entretenir une bonne relation de voisinage ?
Il existe en gros trois types de réseaux physiques raccordés aux interfaces d’un routeur :
- Les réseaux de type « point à point permanent » (Liaison Louée, CVP Frame Relay, VC ATM, etc.) le routeur sait qu’il n’y a, à l’autre extrémité de la liaison, qu’un seul routeur ! Donc s’il émet une donnée sur ce lien, obligatoirement c’est l’autre routeur qui la recevra. De plus sur ce type de lien, si la liaison ou le routeur distant sont HS, il est aisé pour le routeur de l’autre extrémité de le détecter physiquement (perte de « porteuse » sur le lien) ou logiquement (perte de connexion du protocole de niveau 2).
- Les réseaux de type « broadcast » tels que les LAN (Ethernet, Token Ring ou FDDI) sont connectés au routeur par des interfaces LAN. Ils peuvent supporter plusieurs routeurs et si un routeur est HS, les autres ne sont pas sensé le détecter puisque pour eux la connexion au LAN est toujours active ! OSPF identifie ce type de réseau comme des BMA (Broadcast Multi Access). Sur ce type de réseau il devra mettre en place un mécanisme qui lui permettra de savoir si ses routeurs voisins (ses « neighbors » in English !) sont toujours actifs ou non afin de mettre à jour sa LSDB si nécessaire.
- Les réseaux multi-accès n’autorisant pas l’émission de « broadcast ». Ce sont les différents réseaux commutés (RNIS, RTC) ou à commutation de paquets comme X25 ou CVC Frame Relay. Sur ces réseaux une même interface donne accès à différents voisins en fonction de la destination de la connexion. Ces réseaux sont appelés des NBMA (None Broadcast Multi Access).
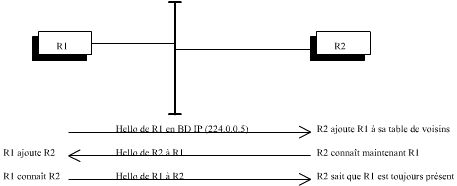 Sur un réseau de type BMA (Broadcast Multi Access) le protocole Hello permet de découvrir qui sont les voisins d’un routeur. Sur un réseau NBMA il faudra préciser au routeur qui sont ses voisins.
Sur un réseau de type BMA (Broadcast Multi Access) le protocole Hello permet de découvrir qui sont les voisins d’un routeur. Sur un réseau NBMA il faudra préciser au routeur qui sont ses voisins.
Un routeur devra échanger régulierement des Hello selon une fréquence paramétrable. Un voisin sera considéré comme perdu au bout d’un temps appelé Dead Interval sans réception de Hello de sa part. Les Hello-times (temps d’intervalles de Hello) et les Dead Interval doivent être tous identiques au sein d’un même réseau NBMA et BMA.
Hiérarchisation …
OSPF est un IGP, il fonctionne donc au sein d’un AS. Si l’AS est très étendu, il y aura:
- Plus d’échange de LSA (un LSA/routeur)
- Plus de place prise par la LSDB au sein de chaque routeur
- Plus de charge CPU pour calculer les arbres SPF depuis la LSDB
Pour optimiser le fonctionnement d’OSPF on peut diviser l’AS en aires (Area). Une aire est un groupe contigu de réseaux et de machines (hosts et routeurs), dont la topologie et l’existence sont invisibles pour les routeurs des autres aires.
Au sein de chaque aire une LSDB particulière est construite selon un OSPF local. Il existe une aire spécifique, appelée aire « Backbone » qui est contiguë à toutes les autres aires, qui leur sert d’aire de transit et qui ne comporte aucun réseau supportant des machines.
Chaque aire possède un identifiant (AreaID) du format @IP, qui comme pour l’IDrouter n’a rien à voir avec un adressage quelconque. L’AreaID de l’aire Backbone est toujours 0.0.0.0.
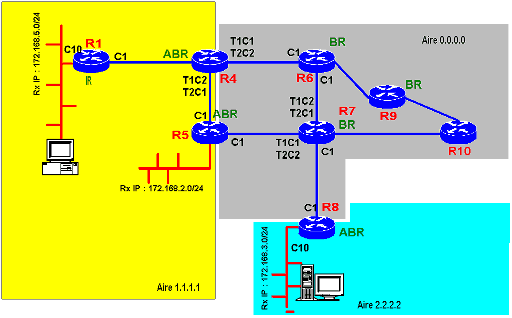 Chaque réseau raccordé aux interfaces d’un routeur est placé dans une aire en lui affectant un AreaID. Dans l’exemple ci-contre, le routeur R4 a le réseau 10.4.0.0/30 placé dans l’Area 1.1.1.1 et le réseau IP 10.1.0.0/30 du lien d’interconnexion avec le routeur R6 placé dans l’aire 0.0.0.0.
Chaque réseau raccordé aux interfaces d’un routeur est placé dans une aire en lui affectant un AreaID. Dans l’exemple ci-contre, le routeur R4 a le réseau 10.4.0.0/30 placé dans l’Area 1.1.1.1 et le réseau IP 10.1.0.0/30 du lien d’interconnexion avec le routeur R6 placé dans l’aire 0.0.0.0.
Le trafic entre deux aires passe forcément par l’aire Backbone (0.0.0.0), tel que suit:
- en intra-aire source : de la source vers le routeur de bordure d’aire backbone selon la table de routage des routeurs internes à l’aire source.
- en inter-aire : d’un routeur de bordure d’aire backbone à un autre selon la table de routage condensée des routeurs d’aire backbone.
- en intra-aire destination : du routeur de bordure d’aire backbone de l’aire destination vers le réseau destinataire, selon la table de routage des routeurs internes à l’aire de destination.
Hiérarchisation des échanges
Comme nous venons de le voir, la division d’un AS en aires permet à OSPF de hiérarchiser le routage. Mais cette hiérarchisation se traduit par des rôles différents dans le process de routage et dans le format des annonces en fonction de la position des routeurs. On dénombre ainsi pour OSPF quatre types de routeurs :
- Internal Router (IR) : routeur ayant toutes ses interfaces directement reliées à des réseaux faisant parties d’une même aire.
- Area Border Router (ABR) : routeur connecté à plusieurs aires.
- Backbone Router (BR) : routeur connecté à l’aire backbone par au moins une interface. Tous les ABR doivent être BR, par contre un BR n’est pas forcément ABR, il peut être IR à l’aire backbone (vous avez compris ou je recommence ?).
- AS Boundary Router (ASBR): routeur échangeant des informations avec des routeurs faisant parties d’un autre AS.
OSPF distingue de plus deux types de réseaux supplémentaire :
- STUB network : réseau de terminaison (un seul routeur connecté). Il n’est pas nécessaire d’activer du Hello, ni d’émettre des LSA sur ce réseau puisqu’il n’y a pas d’autres routeurs pour les interpréter !
- Transit network : réseau de transit supportant plusieurs routeurs, et acheminant donc du trafic inter-STUB network.
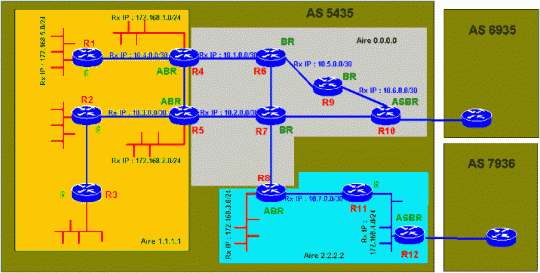 Dans l’exemple ci-contre le type de routeur est indiqué en vert à coté du routeur. Ce type dépend de la localisation dans les aires du routeur. Ainsi R1 est un IR car toutes ses interfaces sont placées dans l’aire 1.1.1.1 alors que R4 est un ABR (routeur de bordure d’aire) puisqu’il a une interface dans l’aire 1.1.1.1 est une autre dans l’aire backbone (0.0.0.0). A noter qu’un ASBR peut être placé dans une aire quelconque ou dans l’aire backbone. Les Stub Network sont les LAN représentés en rouge alors que les Transit Network sont en bleu. Vous noterez que le LAN raccordé à R11 est un Transit Network car il supporte deux routeurs OSPF (R11 et R12).
Dans l’exemple ci-contre le type de routeur est indiqué en vert à coté du routeur. Ce type dépend de la localisation dans les aires du routeur. Ainsi R1 est un IR car toutes ses interfaces sont placées dans l’aire 1.1.1.1 alors que R4 est un ABR (routeur de bordure d’aire) puisqu’il a une interface dans l’aire 1.1.1.1 est une autre dans l’aire backbone (0.0.0.0). A noter qu’un ASBR peut être placé dans une aire quelconque ou dans l’aire backbone. Les Stub Network sont les LAN représentés en rouge alors que les Transit Network sont en bleu. Vous noterez que le LAN raccordé à R11 est un Transit Network car il supporte deux routeurs OSPF (R11 et R12).
La répartition en aires, la hiérarchie des routeurs et des réseaux a amené les concepteurs d’OSPF à diviser et organiser le trafic des informations de routage selon différents types de LSA:
- Type 1 (Router Links Advertisement) : Diffusé au sein d’une aire par les IR et ABR, il décrit les liens vers les routeurs voisins internes à l’aire (Transit network), ainsi que les réseaux LAN raccordés (STUB network).
- Type 2 (Network Links State Advertisement) : Diffusé au sein d’une aire par un DR sur un réseau BMA, il contient tous les LSA type 1 reçus par le DR des différents routeurs connectés au réseau BMA. Nous revenons sur ce principe dans le paragraphe suivant.
- Type 3 (Network Summary Link State Advertisement) : Diffusé au sein d’une aire par un ABR, il décrit les réseaux qui lui sont accessibles en dehors de l’aire de manière condensée.
- Type 4 (AS Boundary Router Summary Link Advertisement) : Diffusé au sein d’une aire par un ABR, il donne le coût de la route entre lui et un ASBR.
- Type 5 (AS External Link Advertisement) : Diffusé à toutes les aires de transit entre AS par les ASBR, il donne les réseaux externes accessibles via l’ASBR émetteur.
D’une manière générale, les routeurs préféreront construire leurs LSDB sur les NLSA (type 2), émises par le DR d’un réseau BMA, plutôt que sur les LSA (type 1) de chaque IR de l’aire.
Les LSA type 3 sont utilisées par les ABR pour connaître le condensé d’une aire, ceux-ci n’ont en effet pas à connaître la totalité de la topologie d’une aire mais simplement le nom des réseaux contenus.
Les LANs de transit (BMA : Broadcast Multi Access)
Nous avons précédemment précisé qu’OSPF distingue différents types de réseau, et que notamment il classe les réseaux LAN qui supportent plus d’un routeur OSPF dans la catégorie des BMA.
Le principe est encore une fois d’optimiser les échanges de LSA entre les routeurs. Si sur un LAN vous avez trois routeurs, ils devraient, en principe transmettre chacun leurs LSA et on émets ainsi trois LSA pour un changement d’état. Par contre, si on défini un routeur maître en charge en charge de compiler les LSA des routeurs du LAN on pourra diminuer le nombre de mises à jour et la réactivité du protocole. Ce routeur est appelé le Designated Router (DR). Par contre si ce routeur devient indisponible, il est impératif qu’un routeur de secours puisse prendre le relais. Ce routeur doit avoir une LSDB rigoureusement identique à celle du DR afin de pouvoir prendre le relais sans problème. Ce routeur est nommé le Backup Designated Router (BDR).
Pour chaque réseau BMA comportant plus d’un routeur, il faudra élire un routeur désigné (DR) et un routeur désigné de secours (Backup DR = BDR). Le routeur désigné est élu par le protocole Hello selon la méthode suivante:
- Tous les routeurs ont un ID et une priorité paramétrable.
- Le routeur désigné sera celui ayant la priorité la plus élevée.
- Dans le cas où deux priorités sont identiques, c’est le routeur ayant l’ID le plus élevé qui sera élu DR.
- Le BDR est élu de la même manière avec, bien sûr, une priorité et/ou un ID inférieur au DR.
Chaque routeur adjacent envoie ses LSA en adresse multicast IP AllDrouters (224.0.0.6), les DR et BDR les reçoivent et les retransmettent à tous les routeurs SPF en adresse multicast AllSPF (224.0.0.5). Donc les paquets IP 224.0.0.6 ne sont lus que par les DR et BDR. Et seuls les DR et BDR émettent avec l’adresse 224.0.0.5.
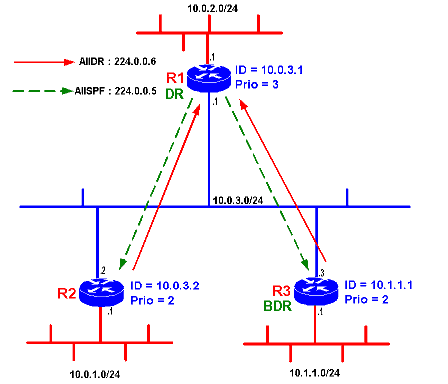 Dans l’exemple ci-contre R1 est élu DR car il possède la priorité la plus élevée (Prio = 3) de tous les routeurs du BMA 10.0.3.0/24.
Dans l’exemple ci-contre R1 est élu DR car il possède la priorité la plus élevée (Prio = 3) de tous les routeurs du BMA 10.0.3.0/24.
Le routeur R3 est élu BDR car il possède un ID plus élevé que R2 à priorité égale (Prio = 2).
Seuls R1et R3 compilent les informations remontées des autres routeurs par les LSA AllDR. R2 ne prend en compte que les LSA AllSPF émises par R1. Aucun autre routeurs du LAN n’émets de LSA AllSPF.
Le routage par les coûts et le TOS
Nous avons précédemment précisé qu’OSPF permet d’implémenter des coûts aux interfaces sortantes et qu’il est capable de router en fonction de la valeur du champ TOS du paquet IP. Ceci suppose donc :
- qu’un routeur OSPF permet l’affectation d’un coût arbitraire et manuel à chacune de ses interfaces.
- qu’il permet également d’associer un coût à différentes valeurs de TOS IP
Rappelons que le TOS IP est un champ de 8 bits de l’entête du datagramme IP qui permet de définir une priorité de routage (champ Précédence de 3 bits) ou des indications sur la nature des routes à emprunter (favoriser le débit ou le délai de traitement ou encore la fiabilité du lien). Je vous renvoi au chapitre 3 du cours IP pour vous rafraîchir la mémoire si nécessaire !
Avec la possibilité d’affecter un coût par interface sortante en fonction du champ TOS vous pouvez ainsi définir des routes vous-mêmes dans le réseau et qui plus est, des routes différentes pour une même destination en fonction de la valeur du champ TOS.
Dans le schéma ci-contre T1C1 veut dire Cout de 1 sur cette interface pour un trafic sortant de champ TOS = 1. C1 veut dire coût de 1 sur cette interface pour un trafic sortant quel que soit la valeur du champ TOS. Dans ce cas, une communication entre le PC de l’aire 1.1.1.1 et le serveur de l’aire 2.2.2.2 utilisera le chemin :
- R1-R4-R6-R7-R8 pour un champ TOS de valeur 1 et pour le chemin aller. En effet, cette route à un coût total de 14 (1+1+1+1+10) contre 15 (1+2+1+1+10) pour la route passant par R5 au lieu de R6. Par contre le chemin de retour pour ce même TOS sera R8-R7-R5-R4-R1 ayant un coût de 14 pour un TOS = 1 au lieu de 15 pour la route passant par R6.
- R1-R4-R5-R7-R8 pour un champ TOS de valeur 2 et pour le chemin aller. En effet, cette route à un coût total de 14 (1+1+1+1+10) contre 15 (1+2+1+1+10) pour la route passant par R6 au lieu de R5. Par contre le chemin de retour pour ce même TOS sera R8-R7-R6-R4-R1 ayant un coût de 14 pour un TOS = 2 au lieu de 15 pour la route passant par R5.
Ce cas d’école (on a jamais vu mettre en place un routage « tournant » aussi tordu dans un vrai réseau !), permet donc de démontrer les capacités de contrôle des routes utilisées en fonction du champ TOS à l’aller et au retour ! Ce principe de routage a été largement inspiré par celui mis en œuvre dans l’architecture DecNet Phase IV de DIGITAL (couche DRP).
Rappelons que l’affectation d’un coût aux interfaces par programmation est facultatif. Si aucun coût n’est affecté par l’administrateur, OSPF calculera un coût par défaut calculé uniquement sur la valeur de la bande passante du support auquel est raccordée l’interface. Ce coût est meilleur que celui de RIP (uniquement nombre de saut) mais reste tout de même relativement simpliste. Donc, quand le réseau est maillé, comme dans le cas de l’aire backbone de notre exemple il est peut-être judicieux d’appliquer un coût manuellement. Par contre pour les cas de R1 ou R8 de notre exemple, on pouvait se dispenser d’affecter un coût puisqu’ils sont des passages obligés !
Conclusion
Nous pourrions encore discuter longuement autour d’OSPF mais nous avons ici vu les caractéristiques « phares ». Ce chapitre n’est qu’une introduction, OSPF mérite un cours complet à lui seul, mais je ne suis pas sûr d’avoir les compétences et le courage nécessaire pour en rédiger un.
Quoiqu’il en soit, si vous avez bien assimilé les éléments du chapitre 4 et de celui-ci, vous avez maintenant une très bonne idée de la différence entre un protocole de routage à état de lien et un protocole de routage à vecteurs de distance. Vous avez j’espère bien compris tout l’avantage qu’il y a à utiliser OSPF sur des réseaux importants.
Pour la partie protocole de routage « purs » nous en resterons là dans ce cours … Passons à la conclusion du cours !
Page précédente | Page Suivante