
En fait sur un plan technique c’est plutôt simple : On cherche à remplir le tuyau !
Et sur un plan économique ce n’est pas plus compliqué : On cherche à payer le moins cher possible … en remplissant le mieux possible les tuyaux !
La solution est donc très simple : On partage, on divise, le débit et le coût entre plusieurs partenaires !
L’aspect économique des choses …
C’est naturel ! Moins c’est cher plus on est heureux ! En matière de réseau, comme en toutes choses d’ailleurs, toutes les entreprises cherchent à obtenir le meilleur service au moindre coût. Pour comprendre l’intérêt économique de la mutualisation il suffit de connaître les modèles de tarification existant actuellement en matière de supports de transmission.
La liaison louée permet de réaliser une interconnexion point à point. Son prix grandit avec la distance à parcourir (à vol d’oiseau entre deux sites) et son débit binaire. Donc plus la liaison est courte et plus son débit est faible, mieux c’est ! L’utilisation de points de concentration intermédiaires permet de diminuer globalement les distances (2 liaisons de 10Km concentrées sur une liaison de 5Km égal 25 Km, contre deux liaisons de 15 Km égal à 30 Km !). Cependant cette topologie peut obliger à appliquer une augmentation de débit sur le lien de concentration (2 liaisons de 10 Km à 64 Kbps sur une liaison de 5 Km à 128 Kbps, contre deux liaisons de 15 Km à 64 Kbps). Dans ce cas, il s’agit de savoir si le fait de passer à 128 Kbps sur 5 km ne serait pas plus cher que de rester à 64 Kbps sur deux fois 5 Km !! Tout dépendra de la longueur de la liaison de concentration … Il faut faire le calcul !
Les raccordements à un backbone opérateur (X25, Frame Relay, Internet, IP, etc.). Ici, généralement, seul reste le critère de débit. L’opérateur pratique généralement une « péréquation » de ses tarifs de raccordement. En fait le réseau opérateur dispose de plus ou moins de points d’accès nationaux et internationaux. Il estime donc qu’en moyenne quelle que soit la localisation du site client la longueur de la liaison de raccordement sera de X Km. Pour des sites sur Paris, par exemple, la longueur sera très inférieure à X mais un site sur le plateau du Larzac sera à une distance bien supérieure à X. Mais l’opérateur calcule ses prix de raccordement sur la valeur X, en priant pour ne pas avoir des clients que sur le plateau du Larzac (entre-nous, il y a peu de chance ! Ils ne sont pas fous les opérateurs !). Bien sûr le prix du raccordement à un débit donné et souvent un peu plus cher qu’une liaison point à point de même longueur et de même débit car l’opérateur ajoute les coûts d’architecture, d’exploitation et de maintenance du backbone ! (Sans oublier sa petite marge quand même !).
Attention : Cette péréquation est souvent appliquée pour les raccordements nationaux ! Pour les raccordements internationaux cela dépendra des accords passés entre l’opérateur fournissant le service de backbone et les opérateurs locaux fournissant les liaisons de raccordement.
Le prix des raccordements à un réseau de type RNIS ou RTC augmente en fonction de la durée de communication et en fonction de sa distance (appels locaux, nationaux ou internationaux). Ce type de réseau devient très onéreux si les communications sont fréquentes, voir constantes ! L’avantage est qu’ils sont très ouverts, depuis un même point on peut contacter successivement de nombreux autres sites quel que soit leur localisation dans le monde. L’inconvénient est qu’il y a souvent un sens unique à l’appel (souvent site distant vers site central) afin d’éviter les croisements d’appels. Pour limiter les coûts de communication, la majorité des opérateurs proposent des accès RNIS et RTC à leur réseau backbone. Le site appel un serveur d’accès au réseau (NAS : Network Access Server) qui achemine le trafic vers un site central connecté au réseau par une liaison permanente. Les NAS étant disséminés dans le réseau les communications RNIS ou RTC sont souvent locales.
Le cas atypique du réseau X25, une innovation essentiellement française, est la facturation au volume ! Ce principe est d’ailleurs repris dans les réseaux GPRS ! Il s’agit cette fois de facturer le volume de données transmis (en plus du prix du raccordement). Dans cette logique il vaut mieux avoir des protocoles peu bavard sur le réseau ! Nous reviendrons sur X25 dans un cours spécifique.
Donc globalement il apparaît clairement que quel que soit le mode de raccordement, le débit d’interconnexion est un facteur économique, il y en a d’autres mais ce n’est pas le sujet de ce cours.
Donc cherchons à diminuer les débits en les partageant ! Seulement sur un plan technique est-ce si simple ? Pourquoi pourrait-on partager un support ?
C’est tout d’abord une question d’application …
En gros, toute transmission informatique ressemble à du gruyère ! C’est bourré de trous, de silences de transmission …On peut diviser les applications en quatre grandes familles :
- les applications clients-serveurs : ce sont généralement des applications qui présentent des masques à remplir aux utilisateurs et génèrent des requêtes vers des bases de données et serveurs d’application centraux. Ici on peut subdiviser cette famille en deux :
- le client-serveur non connecté : ce sont typiquement les applications en mode HTTP (Web), mais également d’autres développement à base de Java ou autres. L’utilisateur rempli un masque, et transmets son masque en validant un bouton. Pendant que l’utilisateur saisi son écran, il n’y a pas de transmission en ligne ! Premier trou dans le gruyère ! Lorsque les données arrivent au serveur, il les traite puis émets une réponse. Pendant le traitement, il n’y a pas de transmission en ligne ! Deuxième trou dans le gruyère (dans l’autre sens de transmission, je vous l’accorde) ! D’autre part pour ce type d’application, le volume de données émis par l’utilisateur est relativement faible. Un écran dépassera rarement les 2 Ko (soit environ 2000 caractères), par contre une réponse serveur pourrait être importante (un gros SELECT sur une base de données).
- le client-serveur connecté (SNA d’IBM, SAP/IPX ou les watchdogs) : ce sont des applications du même type que précédemment si ce n’est qu’il existe un dialogue constant entre le client et le serveur pour vérifier la présence du client. Des requêtes de maintien de sessions permettent au serveur de savoir si le client est toujours présent ou s’il peut libérer la session (et les ressources associées comme une zone mémoire, un pool de variables de contexte, etc.). Dans ce mode le volume reste malgré tout toujours assez faible car les requêtes sont fréquentes mais peu volumineuses. Le problème ici est plutôt le délai de transit, mais c’est un autre sujet … Ici occupons nous du niveau d’utilisation de la bande passante.
- les applications de transfert de fichiers : vous connaissez bien notre star à nous : FTP ! Il en existe des tonnes d’autres comme CFT, TFTP ou encore FTAM. Tout dépend des environnements informatiques. Par contre elles présentent toutes la même caractéristique : elles utilisent toute la bande passante disponible pendant leur transfert. Mais généralement ces transferts sont très épisodiques et il y a de longs moments d’ennuis … Sauf bien sûr si vous êtes un serveur hébergeant des tonnes de MP3 ou de DivX sur Internet ! En général ce type d’application nécessite tout de même des architectures à fortes bandes passantes en général, ou mieux, des supports présentant une bande passante variable comme le Frame Relay ou l’ATM, voir asymétrique, comme l’ADSL ! A noter qu’on classera sous cette catégorie les échanges SMTP (messagerie) qui présentent souvent des messages volumineux en raison des pièces jointes !
- les applications d’émulation d’écrans : il s’agit d’offrir à un terminal peu intelligent, ou incompatible avec un type de serveur, la possibilité d’accéder à un environnement informatique distant. On divise également cette famille en deux :
- les émulations de terminal en mode caractères (TELNET, VT) : le client émet des caractères vers le serveur, celui-ci les interprètent et lui retourne ce qu’il a compris (on appelle ça l’écho distant). Plutôt que d’afficher sur l’écran ce que le serveur a compris certain terminaux permettent d’afficher ce qui vient d’être tapé sur le clavier (on appelle ça l’écho local). Quoiqu’il en soit les caractères sont émis un à un sur la ligne, si vous avec une super secrétaire vous pouvez espérer avoir un meilleur taux d’utilisation de la ligne que si c’est un policier qui frappe avec ses deux doigts (s’il a encore ses deux bras !). Mais dans tous les cas on reste très faible.
Exemple :
une secrétaire chevronnée tapant au rythme effréné de 90 mots minutes (Diantre ! Même ma mère tape pas aussi vite !). Sur une moyenne de 10 caractères par mots on obtient 900 caractères/min soit 15 caractères/sec soit royalement 120 bits/s (8 eb par caractères)… Et pendant la pause café, il est à combien le débit ? - les émulations de terminal en mode graphique : ces applications permettent de représenter graphiquement un environnement informatique distant. Imaginez que votre poste client soit sous un vieil OS comme OS/2 et que vous souhaitiez lui offrir un environnement bureautique « high-tech » comme Office 2000 (Bilou va m’embrasser ! Office 2000 high-tech ! ). Vous êtes dans la mouise ! Il vous faut changer vos postes clients ! Et ça peut être très, très, très coûteux ! Avec des environnements comme Citrix, Terminal Server ou encore X11 vous allez pouvoir vous en sortir en installant un minimum de soft sur le poste client.
- les émulations de terminal en mode caractères (TELNET, VT) : le client émet des caractères vers le serveur, celui-ci les interprètent et lui retourne ce qu’il a compris (on appelle ça l’écho distant). Plutôt que d’afficher sur l’écran ce que le serveur a compris certain terminaux permettent d’afficher ce qui vient d’être tapé sur le clavier (on appelle ça l’écho local). Quoiqu’il en soit les caractères sont émis un à un sur la ligne, si vous avec une super secrétaire vous pouvez espérer avoir un meilleur taux d’utilisation de la ligne que si c’est un policier qui frappe avec ses deux doigts (s’il a encore ses deux bras !). Mais dans tous les cas on reste très faible.
Ce soft va permettre d’établir une connexion avec un serveur d’émulation. Ce serveur va allouer une zone mémoire pour simuler votre écran Windows (pour notre exemple) et y faire tourner ce que vous voulez … à distance ! Le protocole entre le client et le serveur va informer l’un et l’autre des modifications au niveau du clavier, de la souris ou de l’écran. C’est un peu comme si vous regardiez un Windows tourner sur une autre machine par une petite fenêtre (votre écran !) et que vous le télécommandiez avec votre clavier et votre souris ! Cool non ?
Ce type d’application n’est pas forcément gourmand en bande passante, mais généralement les transmissions sont assez constantes. Citrix annonce une bande passante moyenne par session de 15 Kbps environ. Cependant étant donné que le principe est de transmettre des informations sur les zones d’écrans à rafraîchir, il est certain que si vous visualisez une vidéo à distance ou un GIF animé … Vous allez péter le compteur ! Donc un dimensionnement de réseau avec ce type d’application c’est un peu du « petit bonheur la chance » ! Finalement on fait confiance à Citrix et on prend 15 Kbps par session utilisateur (pour X11 il semblerait que ce soit similaire, pour Terminal Server j’ai aucune idée !).
- les applications multimédia : il s’agit ici des applications de type voix (sur IP ou sur Frame Relay ou autres), plus généralement on parle d’intégration voix-données. Mais il s’agit également des applications de visioconférence, de streaming bref, tout ce qui touche à la vidéo. Ici les contraintes sont différentes, les applications de voix ont besoin d’une bande passante constante (entre 16 et 25 kbps par session selon la compression et le nombre de voix simultanées). Les applications vidéo ont également besoin de beaucoup de bande passante (256 Kbps minimum pour une session de visioconférence correcte) mais génère des bursts, la transmission est beaucoup moins linéaire que pour de la voix. Ce sont sans doute les applications qui génèrent le moins de « trous » de transmission. Mais bien sûr, entre deux communications … la bande passante est libre !
Donc, en résumé, quelque soit l’application utilisée, il est extrêmement rare que le support soit utilisé à 100% ! Dans le schéma suivant le lien est partagé par les utilisateurs U1 et U2. Les paquets correspondant sont séparés et des espaces libres de transmission subsistent.
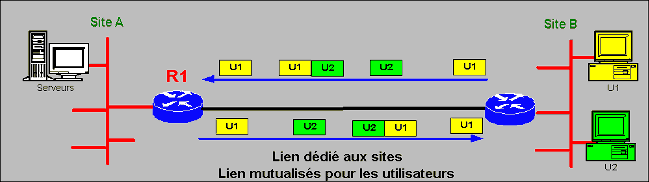
C’est aussi une question d’utilisation …
Le schéma précédent montre l’espace existant entre deux paquets U1 ou deux paquets U2 qui symbolise le fonctionnement asynchrone des applications tel que nous venons de l’expliquer. Mais il montre également qu’il existe des espaces libres entre un paquet U1 et un paquet U2. Cette espace ne relève pas du mode de fonctionnement des applications, mais de l’asynchronisme d’utilisation des applications par les utilisateurs ! Chacun d’eux ne transmets pas forcément en même temps !
Ce paramètre dit de « sessions simultanées » est très important ! Combien d’utilisateurs utiliseront une application en même temps ? C’est toute la problématique dans un dimensionnement de réseaux :
- il faut connaître la bande passante nécessaire par session pour une application donnée
- puis il faut savoir combien de sessions simultanées peuvent être établies en moyenne pour une application !
- enfin il faut identifier chaque application susceptibles d’être utilisée par les clients d’un site donné. Pour chaque application, les paramètres de bande passante par session et de simultanéité de sessions doivent bien sûr être connus !
Avec ces trois paramètres vous pouvez définir quel est le débit nécessaire pour un site donné ! Le problème est qu’il est bien souvent difficile d’avoir une vue précise du deuxième facteur (déjà avoir des informations sur le premier est un vrai bonheur !). En effet le deuxième facteur, même pour une même application, va considérablement varier :
- en fonction du nombre d’utilisateur sur un site. Plus ce nombre est grand plus il y a de chance que le taux (le taux ! Pas le nombre !) de simultanéité pour une même application soit faible. Pourquoi ? Parce que s’il y a beaucoup d’utilisateurs il y a de grandes chances que les métiers soient divers et que les applications utilisées soit en conséquence plus nombreuses (avec bien sûr chacune leur propre bande passante par session !) et l’influence du paramètre 3 grandit !
- en fonction du métier qui va avoir une incidence sur la répartition dans le temps d’accès à l’application. Une agence commerciale composée de vendeurs constamment en clientèle aura un taux de connexion record en fin de journée mais ridicule le reste du temps ! Un centre de production aura une activité assez constante en journée mais nulle en dehors des heures ouvrables.
- en fonction de la nature du site lui-même : un centre informatique qui réalise une duplication de base de données la nuit risque d’avoir besoin d’une énorme bande passante pour pouvoir terminer sa réplication d’application avant la reprise des activités de production normales à 8h ! Or, pendant la journée cette même application ne nécessite pas une bande passante très importante en regard du nombre d’utilisateurs qui l’utilisent !
Il n’y a pas vraiment de recette toute faite, malheureusement ! Dans la majorité des cas on utilise un mixte entre les informations factuelles citées ci-dessus, des éléments de comparaison sur des architectures équivalentes et du « flair » qui augmente avec l’expérience ! Et puis ne nous leurrons pas, l’idéal technique est toujours le plus haut débit possible, l’idéal économique est toujours le plus petit débit possible ! La vérité est quelque part entre les deux extrêmes, mais bien souvent le critère économique fait force de loi (jusqu’à ce que les utilisateurs prennent d’assaut la direction informatique en regard des faibles performances du réseau !).
C’est enfin une question de simultanéité entre sites …
Ce dernier paramètre est intéressant pour le dimensionnement :
- des supports mutualisés entre différents sites
- des architectures « backbone »
- des accès vers les sites centraux
L’expérience montre qu’un lien, supportant le trafic de plusieurs sites, dimensionné à la somme des débits des liens concentrés sera sous utilisé ! En effet, comme pour les utilisateurs, les sites ne trafiquent pas exactement tous en même temps !
Pour comprendre ce fonctionnement nous allons changer de représentation du flux de données. En effet, la notion d’espace entre les paquets telle que nous l’avons expliqué précédemment est pour le moins, peu académique, il est préférable de revenir à une représentation plus universitaire ! Dans le schéma suivant nous avons deux sites connectés à un site de concentration. Les sites B et C ont chacun une typologie de trafic propre mais relativement similaire car ils utilisent les mêmes applications. Cette typologie est représentée par les graphes A et B.
Sur ces graphes la courbe représente la bande passante utilisée en fonction du temps. On notera que le trafic est assez sporadique et en pointe. Ce profil pourrait différer d’une application à l’autre mais globalement c’est une représentation courante. L’important est de noter la grande partie de bande passante inexploitée (zone quadrillée sur les graphes) par chaque site sur son lien dédié.
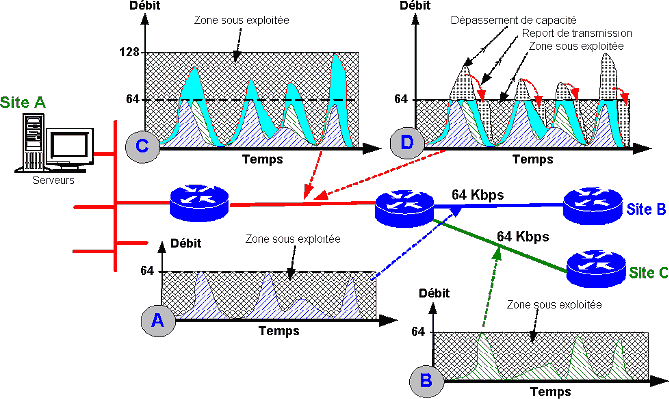
Les graphes C et D présentent une courbe rouge qui est en fait la somme des débits des sites en fonction du temps (somme des courbes) sur le lien mutualisé vers le site A.
Si ce lien est dimensionné à 128 Kbps (graphe C) toute la zone de trafic est prise en charge et entre dans la bande passante offerte par le support. Par contre on note l’importante zone de bande passante inutile, seul un tiers des capacités du support est utilisé ! Donc un lien mutualisé ayant une bande passante égale à la somme des bandes passantes des liens qu’il mutualise n’est pas véritablement une opération rentable !
Si maintenant on dimensionne ce lien à 64 Kbps (graphe D) soit donc à la moitié de la somme des débits d’entrée on remarque que la zone sous exploitée est beaucoup plus restreinte. Par contre nous sommes confrontés à un autre problème ! Des pics de trafic dépassent la capacité du support, en théorie ce trafic serait donc perdu !
Ce phénomène s’appelle la congestion. Il y a un excédent de trafic que le lien ne peut acheminer. Pour gérer ce problème, le graphe D propose de reporter la transmission du pic de trafic à un moment où le lien est moins chargé. C’est une méthode mais il y en a d’autres que nous abordons dans le chapitre suivant.
A noter qu’ici je n’ai pas évoqué le cas où un site distant (B ou C ici) émettrait des données au-delà des capacités de son lien dédié (64 Kbps ici). Il y aurait donc également une congestion sur le lien dédié du site ! Ceci est tout à fait possible puisque le débit d’entrée sur l’équipement d’accès au support peut-être celui d’un LAN (Ethernet à 10 Mpbs par exemple !).
Conclusion du chapitre
Pas si simple n’est-ce pas ? Il vous apparaît maintenant comme évident qu’il est possible de mutualiser les liens, que cela est justifié économiquement et techniquement. Mais il apparaît également qu’il n’est pas si simple de gérer et surtout d’évaluer (dimensionner) cette mutualisation. Enfin, comment gérer le cas où le trafic total dépasse les capacités du support ?
Tout vous est dévoilé dans le chapitre suivant !