
La base … Plus simple, tu meurs !
Rappelons déjà ce que nous savons :
- RIP est un IGP. A ce titre, il est utilisé par les routeurs, au sein d’un AS, pour construire les tables de routage.
- RIP est un protocole à vecteurs de distances. A ce titre, tous les routeurs du réseau, qui l’implémente, émettent, à intervalles réguliers, la totalité de leur table de routage sur toutes leurs interfaces.
Puis plaçons les concepts simples :
- nous savons qu’un protocole de routage, quel qu’il soit, associe un coût à une route. La notion de coût (la façon dont on le calcule, les paramètres pris en compte pour le calculer) différe d’un protocole à l’autre. Pour RIP, le coût est un nombre de sauts (les hops), on parle de hop-count. Un hop, c’est un saut de routeur ! Si pour atteindre une destination je dois traverser 5 routeurs, ma route aura un coût de 5 !
- nous savons également que tous les protocoles définissent une limite de coût au-delà de laquelle une route est considérée comme invalide. Ceci permet donc de déclarer une route hors service (notamment si un lien de la route est HS !). Ce « coût limite » varie d’un protocole à l’autre, puisque la notion de coût varie d’un protocole à l’autre (je suis sûr que vous pouviez le deviner tout seul ! Mais je préfére mettre les points sur les « i », pour ceux qui me regardent comme si j’étais un extra-terrestre, là-bas, dans le fond de la salle !). Bref, pour RIP, la limite de coût est 15 sauts. Au-delà, à 16 sauts (je précise ! 15,5 sauts ça n’existe pas !), la route est considérée comme invalide. Au commencement …
« Dieu créa la femme …« . Heu .. Excusez-moi, je m’éloigne du sujet !
Au commencement un routeur est ignare ! Lorsque vous l’installez sur le réseau, il n’a pas de table de routage, il ne sait même pas ce que vous attendez de lui. Pour l’instruire vous allez le programmer ! Après avoir branché les interfaces réseaux et l’avoir mis sous tension (c’est conseillé !), vous accédez à son logiciel d’administration (la méthode varie d’un matériel à l’autre !), et vous le programmez.
Vous allez lui indiquer ses adresses IP par interfaces réseaux (comme à n’importe quelle machine IP, voir le cours IP !). Puis vous allez voir sa table de routage, et surprise ! Il n’y a rien dedans ! Enfin presque … Il y a juste les adresses des réseaux dans lesquelles sont programmées les interfaces du routeur.
Par exemple, si vous avez déclaré une interface Ethernet0 avec l’adresse 10.0.0.1/8 (je ne fais pas de rappel sur les notations d’adresses IP ! Vous avez vu tout ça dans le cours IP !) et une interface Serial0 avec l’adresse 11.0.0.1/8, vous aurez dans la table de routage :
- 10.0.0.0 via Ethernet0 (10.0.0.1) – Coût = 0 – Directly Connected
- 11.0.0.0 via Serial0 (11.0.0.1) – Coût = 0 – Directly Connected
Ceci indique que les réseaux 10.0.0.0 et 11.0.0.0 sont respectivement accessibles par les interfaces Ethernet0 et Serial0 où ils sont directement connectés. Le coût de la route est donc nul !
Exemple :
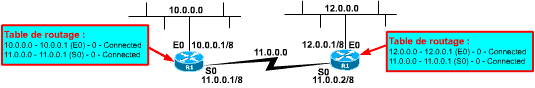
Super donc ! Le routeur sait dans quels réseaux il a les pieds ! On avance ! Mais il serait assez intéressant qu’il sache dans quels réseaux se trouvent les pieds de ses voisins !
Un peu plus avant …
Pour rendre le routeur plus intelligent, vous allez de nouveau accéder à son administration pour lui dire (dans son langage !) : Enclenche ton routage RIP ! Vous faites bien sûr la même chose sur tous les routeurs du réseau !
Puis vous retournez examiner la table de routage. Tout d’abord il n’y a rien ! Puis petit à petit vous voyez apparaître les réseaux distants ! Eurêka ! Ça marche ! Oui, mais comment ?
C’est très simple :
-
Chaque routeur a commencé par émettre des updates RIP sur toutes ses interfaces en broadcast IP. Ces updates contenaient la totalité de leur table de routage, sauf le réseau sur lequel est émis l’update. En effet, il est inutile d’indiquer le réseau 10.0.0.0 aux routeurs qui sont également sur le réseau 10.0.0.0 ! Ils ont également les pieds dedans ! Pour chaque réseau annoncé, le routeur associe, dans l’update, la valeur de coût qu’il a dans sa table de routage.
-
Toutes les machines IP reçoivent les paquets IP émis en « broadcast ». Elles examinent le champ protocole et voient que c’est de l’UDP dans le paquet ! Elles remontent le segment UDP à leur couche UDP qui examine le port UDP destination. Ce port indique que le contenu est une mise à jour RIP ! Seules les machines qui ont un process RIP actif vont prendre en charge l’update, les autres l’ignorent. C’est pourquoi il faut bien enclencher le process RIP sur tous les routeurs !
-
Le routeur qui traite l’update examine chaque entrée. Rappelez-vous ! Une entrée est formée d’une destination (adresse réseau) et d’un coût :
-
Si l’entrée n’existe pas dans sa table de routage, il incrémente de 1 le coût (puisqu’il faut passer par un autre routeur pour atteindre la destination) puis il inscrit dans sa table :
-
l’adresse de destination indiquée dans l’entrée de l’update
-
le coût associé qu’il vient d’incrémenter
-
l’adresse IP de l’émetteur de l’update (next-hop)
-
le délai écoulé depuis la réception de cet update (il enclenche un timer appelé le hold-time timer).
-
Il ajoutera également diverses informations comme :
-
le nom du protocole de routage par lequel il a appris cette route, pour notre cas : RIP. En effet au sein d’un même routeur on peut très bien faire tourner plusieurs protocoles de routage simultanément ! Il est donc important de savoir par quel protocole on a appris une route.
-
l’interface de sortie du routeur par laquelle on peut atteindre le next-hop (adresse de l’émetteur de l’update)
-
priorité du protocole de routage. Si une même destination est apprise par deux protocoles de routage différents, ce paramètre permet de préférer la route indiquée par l’un plutôt que par l’autre.
-
etc.
-
-
-
Si l’entrée existe déjà avec une adresse de next-hop différente de l’adresse de l’émetteur, le routeur compare les coûts (après avoir incrémenté de 1 le coût indiqué dans l’update) :
-
Si le coût de l’update est inférieur il remplace l’entrée dans la table de routage par celle de l’update.
-
Sinon il ignore l’update.
-
-
Voilà le process standard. J’ai volontairement ignoré quelques aspects que nous aborderons dans le chapitre suivant.
A fond dans le détail !
Comme un exemple vaut mieux qu’un long discours, voici un exemple, accompagné d’un long discours !!
Phase 1 : Programmer le réseau
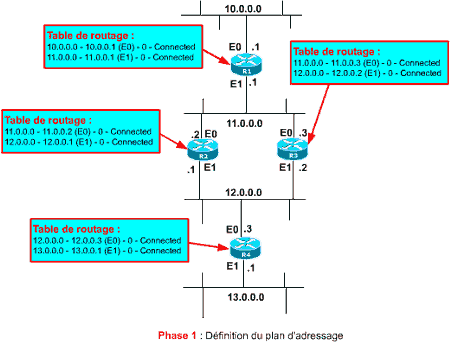 Soit le réseau ci-contre composé des routeurs R1, R2, R3 et R4 interconnectant les réseaux IP 10.0.0.0 à 13.0.0.0. Après avoir installé les routeurs sur site, les avoir mis sous tension et avoir raccordé les câbles réseaux, il est temps de les programmer !
Soit le réseau ci-contre composé des routeurs R1, R2, R3 et R4 interconnectant les réseaux IP 10.0.0.0 à 13.0.0.0. Après avoir installé les routeurs sur site, les avoir mis sous tension et avoir raccordé les câbles réseaux, il est temps de les programmer !
Vous allez définir dans un premier temps, sur chacune des interfaces les adresses IP et les masques associés. Ceci va permettre aux routeurs de savoir dans quels réseaux ils ont les pieds ! Si vous ne programmez rien d’autre et si vous examinez les tables de routage vous obtenez le contenu du schéma ci-contre.
Vous remarquez que les routeurs connaissent les réseaux qui leurs sont directement raccordés mais rien d’autre ! Notamment R2 et R3 ignorent la présence des réseaux 10.0.0.0 et 13.0.0.0, de la même manière que R1 ignore l’existence des réseaux 12.0.0.0 et 13.0.0.0, et R4 ignore les réseaux 10.0.0.0 et 11.0.0.0. Si des paquets leurs étaient envoyés avec ces adresses destinations, ils ne sauraient pas quoi en faire et les jetteraient !
Phase 2 : Activation de RIP
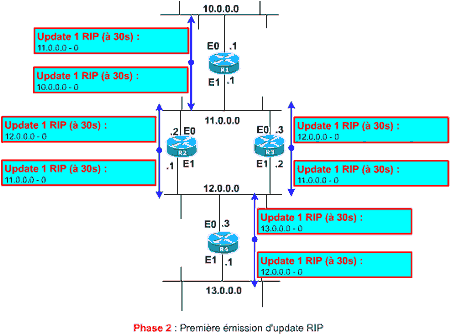 Pour remédier au problème vous accédez de nouveau à l’administration de chaque routeur et vous activez le process RIP. Immédiatement, ou au plus tard dans les 30 secondes, chaque routeur émet un premier update. Bien sûr les updates ne sont pas forcément émis en même temps par tous les routeurs (je précise, au cas où …). Le schéma ci-contre présente le contenu de ces updates.
Pour remédier au problème vous accédez de nouveau à l’administration de chaque routeur et vous activez le process RIP. Immédiatement, ou au plus tard dans les 30 secondes, chaque routeur émet un premier update. Bien sûr les updates ne sont pas forcément émis en même temps par tous les routeurs (je précise, au cas où …). Le schéma ci-contre présente le contenu de ces updates.
Vous remarquez :
- que les updates contiennent la table de routage de chaque routeur. L’update est formé d’entrées (lignes). Chaque entrée est constituée de l’adresse réseau annoncée (la destination) et d’un coût associé. Ce coût est celui indiqué dans la table de routage (ici tous les coûts sont à 0, puisque les réseaux annoncés sont tous directement raccordés aux routeurs émettant les updates). Je vous rappelle que le coût pour RIP correspond à un nombre de routeurs à traverser.
- que les updates sont émis sur toutes les interfaces de chaque routeur
- que le numéro du réseau sur lequel est émis l’update n’est pas inscrit dans l’update. Par exemple R1 n’annonce pas le réseau 11.0.0.0 dans l’update émis sur 11.0.0.0. En effet, les routeurs R2 et R3 n’ont pas besoin de cette information puisqu’ils ont également les pieds dans le réseau 11.0.0.0.
Phase 3 : Première initialisation des tables de routage
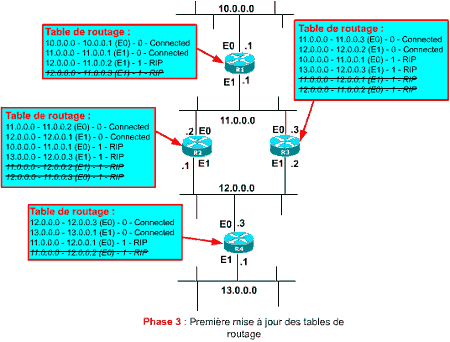 Chaque routeur examine les updates reçus. Ils incrémentent systématiquement de 1 les coûts annoncés puisqu’ils considèrent que les routeurs émettant les updates devront être franchi pour atteindre les destinations indiquées.
Chaque routeur examine les updates reçus. Ils incrémentent systématiquement de 1 les coûts annoncés puisqu’ils considèrent que les routeurs émettant les updates devront être franchi pour atteindre les destinations indiquées.
Tous les routeurs ajoutent dans leurs tables les destinations qui ne leurs sont pas encore connues. Par contre, si une entrée est déjà connue, le routeur compare le coût annoncé et l’adresse de l’émetteur de l’update :
- si le coût de l’update est inférieur à celui de la table de routage, l’entrée de l’update remplace celle de la table
- si le coût est supérieur ou identique, l’update est ignoré
Le schéma ci-contre illustre le contenu des tables de routage après traitement du premier update par les routeurs.
Vous remarquerez que R1 a reçu deux annonces pour 12.0.0.0, une de la part de R2 et une autre de R3. L’entrée de R3 a été ignorée par R1 (barrée dans le schéma) car son coût n’était pas meilleur que l’entrée annoncée par R2 qui a été traitée avant (mais cela aurait pu être l’inverse !). Il en est de même pour R4 vis à vis de l’annonce simultanée de 11.0.0.0 par R2 et R3.
A noter également que R2 reçoit, par son interface E1, une annonce de R3 pour le réseau 11.0.0.0, bien sûr R2 l’ignore (barrée dans le schéma) puisqu’il a accès à ce réseau directement par son interface E0 ! C’est d’ailleurs la même chose pour R3 à qui R2 annonce 11.0.0.0 !
Chaque entrée de la table de routage qui est initialisée suite à réception d’un update est construite telle que suit :
destination – adresse de l’émetteur de l’update (interface sur laquelle est accessible l’émetteur de l’update) – coût de la route – protocole qui a annoncé la route
Vous remarquerez enfin que R1 ne connaît toujours pas le réseau 13.0.0.0 et que R4 ne connaît pas 10.0.0.0. Il va falloir attendre le prochain update !
Phase 4 : Émission du deuxième update
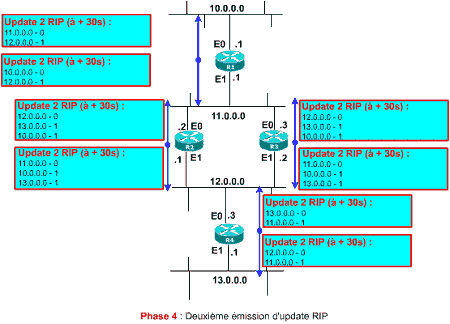 Comme précédemment, les routeurs émettent leurs updates contenant la totalité de leur table de routage, sur toutes leurs interfaces.
Comme précédemment, les routeurs émettent leurs updates contenant la totalité de leur table de routage, sur toutes leurs interfaces.
Pour l’anecdote, vous remarquerez que l’update émis par R1 sur le réseau 10.0.0.0 est totalement inutile puisqu’il n’y a aucune machine pour interpréter son annonce. Mais comment voulez-vous que le routeur le sache ? Pour information, certains constructeurs permettent, par un jeu de commandes, d’indiquer au routeur qu’il est inutile d’émettre des annonces sur certaines interfaces. Ceci permet de limiter la charge sur des réseaux locaux de terminaison. Mais attention, il faut être certain qu’aucun équipement n’a besoin de ces annonces sur le LAN (autre routeur, serveur, etc.).
Vous remarquerez que l’update émis sur le réseau 11.0.0.0 par R1 contient le réseau 12.0.0.0. Ceci suppose que R1 peut donner accès à 12.0.0.0, ce qui est totalement faux ! 12.0.0.0 n’est accessible que par R2 et R3 ! Les connaisseurs, en voyant ce schéma, risquent de sauter au plafond (attention les bosses !). Calmez-les, on parlera de ça dans le chapitre suivant. Sachez simplement que c’est partiellement faux !
Comme précédemment les réseaux 11.0.0.0 et 12.0.0.0 sont annoncés l’un à l’autre par R2 et R3 ce qui est inutile !
Phase 5 : Deuxième mise à jour de table
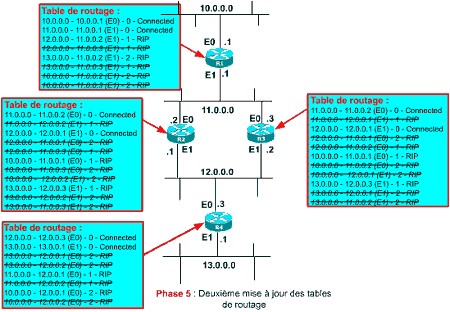 Je ne reprends pas en détail l’algorithme de traitement des updates. Vous remarquerez dans le schéma suivant, que chaque routeur ajoute les entrées qui lui sont inconnues et ignore les entrées présentant un coût supérieur ou égal. C’est finalement très simple !
Je ne reprends pas en détail l’algorithme de traitement des updates. Vous remarquerez dans le schéma suivant, que chaque routeur ajoute les entrées qui lui sont inconnues et ignore les entrées présentant un coût supérieur ou égal. C’est finalement très simple !
Au final, après ce traitement :
- les tables de R2 et R3 n’ont pas été modifiée, elles avaient déjà toutes les informations nécessaires
- R1 a appris la route pour 13.0.0.0 (via R2) et R4 a appris la route pour 10.0.0.0 (via R2 également).
- tous les réseaux sont connus par tous les routeurs ! Alléluia !! Enfin presque ….
Ce qu’il faut retenir …
En synthèse :
- RIP est un protocole à vecteurs de distances de type IGP
- RIP émet la totalité de la table de routage des routeurs toutes les 30 secondes (Hello-time).
- Le coût RIP est un nombre de sauts. Au-delà de 15 sauts la route est invalide. La meilleure route est celle présentant le moins de sauts (le coût le plus faible).
Tout à l’air rose, mais …
La méthode semble bonne, mais à bien y réfléchir :
- R1 a du attendre deux updates (soit au moins une minute !) pour avoir connaissance du réseau 13.0.0.0 qui se trouve à deux sauts (R2 ou R3 puis R4) de lui. A votre avis combien de temps devrait-il attendre pour avoir connaissance d’un réseau qui se trouve à 15 sauts de lui ?
- Les updates RIP véhiculent uniquement une adresse réseau sans masque associé. Comment sera construit le routage si mon réseau utilise des sous-réseaux IP ?
- Si R2 tombe HS comment R1 fait-il pour atteindre le réseau 13.0.0.0 ? Certes, il passera par R3, mais combien de temps faudra-t-il pour reconfigurer le routage ? Comment sera-t-il informé de l’indisponibilité de R2 ?
- Si R4 tombe HS, combien de temps faudra-t-il à R1 pour savoir que le réseau 13.0.0.0 n’est plus atteignable ?
- Est-il normal que R1 émette une annonce pour 12.0.0.0 à R2 et R3 alors qu’il ne contrôle pas ce réseau ?
- etc …
Allez vite au chapitre suivant, je vais tenter de répondre à ces quelques questions …
Page Précédente | Page Suivante