
Protocoles à « vecteurs de distance » et « états de lien » par l’image …
Il existe deux catégories de vacanciers :
-
 les aventuriers qui ne vivent que pour les sensations fortes et les surprises
les aventuriers qui ne vivent que pour les sensations fortes et les surprises -
 les planificateurs qui examinent, analysent, prévoient, bref ! Qui doivent tout savoir avant de décider !
les planificateurs qui examinent, analysent, prévoient, bref ! Qui doivent tout savoir avant de décider !
Les premiers lorsqu’ils partent en vacances, c’est une aventure : On verra bien comment ça se passe ! Pour les seconds, c’est une galère, le parcours du combattant ! Il faut qu’ils sachent tout à l’avance (où j’arrive, qui m’accueille quand je pars et comment, etc). Personnellement, je suis plutôt dans le deuxième groupe (je sais … vous vous en fichez !).
Supposons qu’un individu de chaque catégorie souhaitent se rendre à Djibouti (pourquoi pas ?) depuis Paris :
- le premier (l’aventurier), trouve un panneau marqué « Djibouti 3400 Km via Marseille » (Si ! Si ! Il y en a un ! Place Vendôme à Paris !) et un autre marqué « Djibouti 3500 Km via Le Caire » (Si ! Si ! Ce second panneau est planté à la Porte Maillot juste avant de prendre le périphérique intérieur !). Que fait-il ? Je vous le donne en mille, ni une ni deux, il passe par Marseille. A Marseille il cherchera un panneau pour Djibouti (en espérant que ce ne soit pas via Paris !).
- le second (l’anxieux, le planificateur), ne se contente pas d’une information si succincte ! D’accord, « 3400 Km via Marseille » et « 3500 Km via Le Caire », mais comment je vais à Marseille, je passe par où ? J’y vais en voiture, en avion, à cheval, à pied ? Je vais mettre combien de temps ? Et si l’avion est en panne, j’y vais comment ? Et puis, surtout, arrivé à Marseille ou au Caire, je prends quelle destination ? J’utilise quel moyen de transport ? Combien de temps je vais mettre ? etc … (Bileux, le type !)
Le premier se contente d’une information de proximité qui lui indique une direction et un coût. Il va choisir la route via Marseille car son coût est moindre (le nombre de kilomètres).
Le second demande un détail de la route à suivre. Pour aller à Marseille prendre le train à Gare de Lyon, 70€ de ticket, 450 Km, 3 heures. Puis prendre l’avion à Marignane direction Djibouti, pas d’escales, 2950 Km, 1000€ de billet, 5 heures de vol. Il existe également une possibilité de se rendre à Djibouti par Le Caire, prendre l’avion à Charles de Gaulle, escale à Dubai, 3500 Km, 1200€ de billet, 7 heures de vol. etc … Le second va calculer le coût de la route lui-même : 450 Km + 2950 Km = 3400 Km contre 3500 Km direct. Il passe aussi par Marseille car son critère de choix est également le nombre minimum de Km (je sais, il est finalement guère plus futé que le premier !). Mais l’important est que son choix n’est pas basé que sur l’information du panneau de direction, il a détaillé la route est recalculé le coût. Si la distance entre Marignane et Djibouti changeait (elle est bien bonne celle-là !), il pourrait recalculer le coût facilement.
Toute la différence est là ! Le premier fonctionne en « vecteurs de distances » alors que le second fonctionne en « états de liens » !
Le premier considère une route uniquement sur une indication de direction et de coût émanant d’une information de proximité (le panneau). Le second considère une route sur une analyse de ses différentes composantes. A l’inverse du premier, il a connaissance du détail de la route. Pour être simpliste et abrupte on pourrait dire que le second réfléchi et pas le premier !
La réalité …
 L’image précédente illustre bien la différence fondamentale entre les deux approches en matière de construction des tables de routage. Transposons donc l’image à la réalité.
L’image précédente illustre bien la différence fondamentale entre les deux approches en matière de construction des tables de routage. Transposons donc l’image à la réalité.
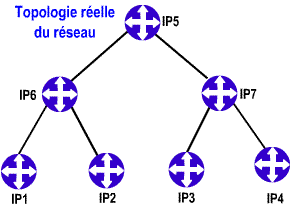
Prenons pour exemple la topologie réelle du réseau ci-contre et examinons comment chacun des deux types de protocoles va transcrire cette topologie dans une table de routage.
Vecteurs de distance
Les protocoles de ce type ont un fonctionnement assez simple :
-
- tous les routeurs du réseau transmettent à intervalles réguliers (les Hello-Time) des mises à jours (des « updates ») sur toutes leurs interfaces.
- ces updates sont des paquets IP, émis en broadcast, et contenant la totalité de leur table de routage (heu … presque ! Mais on verra ça plus tard !).
- tous les routeurs qui reçoivent ces updates en comparent le contenu avec les entrées de leur table de routage. Ils considérent trois paramètres :
- la destination : si une destination apparaît dans un update et qu’elle n’existe pas dans leur table, ils ajoutent l’entrée à leur table. L’entrée sera constituée de l’adresse de destination indiquée, du coût de route indiqué, et de l’adresse du routeur qui a émis l’update permettant d’ajouter l’entrée. Cette adresse est en fait l’adresse IP source du paquet IP contenant l’update de référence.
- le coût : si une destination annoncée dans un update existe dans la table de routage mais avec un coût différent, le routeur procéde à la mise à jour du coût.
- l’adresse de l’émetteur : si une destination existe dans la table de routage mais a été enregistrée avec une adresse de next_hop (adresse de l’émetteur de l’update) différente de l’adresse émetteur de l’actuel update, le routeur compare les coûts. Si le coût indiqué dans l’update est supérieur au coût de l’entrée existante, il ignore l’information. A l’inverse si le coût indiqué dans l’update est inférieur, il remplace l’entrée existante dans la table de routage par l’information de l’update.
 L’algorithme est très simple (Enfin ! J’ai quand même négligé quelques aspects que nous traiterons plus tard …) ! Mais ça marche ! Nous étudierons cela en détail avec RIP … Certes, il y a quand même quelques « loups dans le bois » !
L’algorithme est très simple (Enfin ! J’ai quand même négligé quelques aspects que nous traiterons plus tard …) ! Mais ça marche ! Nous étudierons cela en détail avec RIP … Certes, il y a quand même quelques « loups dans le bois » !
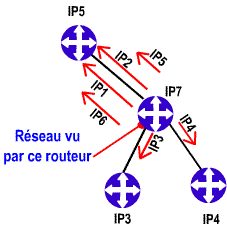
Au final, le routeur se croit le centre du monde (du moins du réseau). Toutes les destinations sont des routes qui prennent des directions via des routeurs adjacents. Ce sont donc des vecteurs. Chaque route à un coût, c’est le poids du vecteur. Vous savez maintenant pourquoi on appelle cela un protocole à vecteurs de distances ! Le concept est imagé dans les deux schémas présentés. Le schéma du haut indique la topologie réelle du réseau, chaque routeur donne accès à un réseau IP (IP1 à IP7). Le schéma de droite présente la vue que le routeur contrôlant IP7 a du réseau. Il a l’impression d’être le centre du réseau, les autres réseaux IP lui apparaissent accessible via ses voisins (IP5, IP3 et IP4). Chaque réseau de destination est un vecteur vers un voisin, d’une longueur variant avec le coût de la route. Le vecteur IP1 est plus long que le vecteur IP6, son poids est plus important, car il faut faire 2 sauts pour atteindre IP1 contre un seul saut pour IP6.
États de liens
Lorsque nous étudierons RIP nous verrons que les protocoles à vecteurs de distance présentent au moins deux inconvénients majeurs :
-
-
la charge réseau induite par les updates. En effet, chaque routeur émet régulièrement sur le réseau l’ensemble de sa table de routage. Ce trafic induit fini par ne pas être négligeable, notamment dans le cas de grands réseaux.
-
mais surtout, le protocole n’est pas très réactif (nous verrons pourquoi avec RIP !). On parle de « latence » ou de « délai de convergence » longs.
-
Il a donc été nécessaire d’imaginer un autre type de fonctionnement. Nous ne l’étudierons pas ici en détail, ce sera l’objet d’un cours spécifique. Le principe est le suivant :
-
-
Chaque routeur transmet, comme précédemment, des updates à ses voisins (les routeurs voisins, pas les machines IP bien sûr !).
-
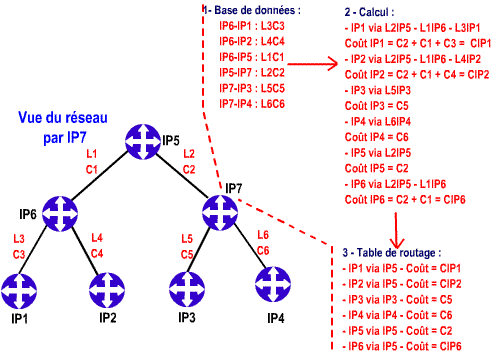
Ces mises à jour sont placées dans des paquets IP émis en multicast (tiens ! Ça change !). Selon la nature des informations émises l’adresse de multicast peut être différente, elle permet de s’adresser à des routeurs ayant des rôles particuliers dans le réseau. Ces updates indiquent non plus des destinations associées à des coûts, mais des descriptions de liens (des link states). Comme chaque lien est forcément associé à une adresse IP réseau il est identifié par cette adresse. Il est ensuite décrit par sa nature (LAN, Point à point, Multipoint), son coût d’accès (notion très subjective, variant d’un protocole à l’autre), son état (actif, down, shut, etc.), etc. Enfin le lien est également associé à un identifiant de routeur qui lui donne accès (le routeur qui est branché sur le lien).
-
Ces informations sont stockées dans une base de données du routeur. Par un algorithme (de la mort !), le routeur va déterminer quelles suites successives de liens et de routeurs sont possibles pour atteindre une destination, c’est le calcul de routes. Si pour une même destination il y a plusieurs routes possibles, il validera, dans sa table de routage, celle de coût le plus faible. Le coût d’une route correspond à la somme des coûts des liens la composant.
-
A chaque update, le routeur examinent les changements pour chaque lien par rapport aux précédentes mises à jour. S’il n’y a pas de changement il ne recalcule pas les routes et n’émets pas de mises à jour à ses voisins (c’est là que ça change !). Par contre s’il y a un changement, il ne relaie vers ses voisins que l’information ayant changée (là aussi ça change ! Il n’envoie pas sa table de routage complète !).
-
Donc les différences fondamentales avec un protocole à vecteurs de distances sont :
-
-
les routeurs n’émettent des updates que lorsque des liens changent d’états (coûts, indisponibilité, etc.)
-
les updates émis ne contiennent que des descriptions de liens ayant changé d’état, ils sont donc moins volumineux
-
grâce aux updates d’états de liens, les routeurs stockent dans leurs bases de données une véritable carte topologique du réseau et de son état
-
les routeurs retransmettent immédiatement les mises à jour à leurs voisins, ils compilent leur table de routage après, le protocole est donc beaucoup plus réactif !
-
Malheureusement, il y au moins trois inconvénients (il y a toujours des inconvénients ! Rien n’est parfait en ce bas monde !) à l’utilisation de ce type de protocole :
-
-
il faut des routeurs possédant des performances CPU et des capacités mémoires supérieures à celles nécessaires pour les vecteurs de distance. C’est plus cher !
-
ce type de protocole très réactif nécessite des réglages précis des timers de transmission car sa réactivité peut justement nuire à la stabilité du routage (si on change toutes les tables pour une micro-coupure de liens, par exemple !).
-
enfin, si un jour j’ai le courage de rédiger un cours sur OSPF, vous verrez que ces protocoles sont assez complexes à mettre en œuvre
-
Quels protocoles pour quelle famille ?
Les protocoles de routage se divisent donc en deux familles. J’ai délibérément retiré les protocoles de routage externe (EGP et BGP) qui ne peuvent être classés dans l’une ou dans l’autre famille. En effet, ils établissent des connexions avec d’autres routeurs et échangent des informations selon des mécanismes très différents. Pour BGP la notion de coûts est de plus très complexe et n’a rien à voir avec les coûts des IGP.
J’ai également éliminé les protocoles IS-IS et ES-IS car je ne les connais pas assez pour les classifier ! Si quelqu’un à un avis éclairé sur la question, je suis preneur !
| Protocole | Description |
|---|---|
|
Les protocoles à vecteurs de distances |
|
| RIP | Routing Information Protocol (version 1 & 2) : Le plus ancien, le plus simple mais encore très utilisé ! |
| IGRP | Interior Gateway Routing Protocol : Protocole propriétaire Cisco, mais comme Cisco est très implanté dans le monde du réseau, on le trouve très souvent. |
| E-IGRP | Extended IGRP : Apparut avec la version logicielle 11 de Cisco, il supplante peu à peu l’IGRP. Il offre des fonctions plus élaborées. |
| Les protocoles à états de liens | |
| OSPF | Open Shortest Path First : Un « must », très complet, très performant, très élaboré, mais très compliqué et consommateur de ressources dans les routeurs. On le réserve généralement à de grands réseaux. |
Conclusion du chapitre
J’espère avoir été suffisamment clair sur le concept. Si vous n’avez aucune connaissance du routage, il est probable que ce chapitre vous aura semblé un peu nébuleux, obscur, indigeste, etc. Rassurez-vous, après une explication détaillée du fonctionnement de RIP vous comprendrez parfaitement le fonctionnement d’un protocole à vecteurs de distances et aborderez donc plus facilement la différence avec l’état de liens ! Donc rendez-vous au chapitre suivant : RIP.