
C’était, jusqu’à il y a peu, la méthode la plus courante. Elle présentait un bon « rapport qualité – prix ». Relativement peu onéreuse (du moins tant que le secours n’est pas activé), simple à implémenter et assez fiable. Elle est maintenant souvent remplacée par le secours ADSL (du moins en France), nous y reviendrons.
Remarque : Plus récemment encore on voit apparaître des solutions de secours 3G+ (UMTS) soit donc par voie hertzienne … Le Top, mais attention à la perte de débit en mode secours.
Le principe est simple :
* Le routeur de site est équipé d’une carte RNIS et il est connecté à un accès RNIS
* Lorsque le lien nominal est hors service, il active une connexion RNIS en remplacement
* Lorsque le lien nominal revient à l’état UP (par opposition à DOWN ! J’aime développer vos capacités linguistiques !), il coupe la connexion RNIS et renvoi le trafic sur le lien nominal
Il existe deux méthodes principales :
* Le secours RNIS de bout en bout où le routeur du site A va appeler directement par RNIS le routeur du site B. Ceci implique donc que le routeur du site B soit également équipé d’une carte RNIS ! C’est le sujet de ce chapitre.
* Le secours RNIS par NAS où le routeur du site A va appeler un équipement spécial du backbone. Celui-ci va « abouter » sa connexion RNIS au backbone et ainsi le site retrouve l’accès au réseau. Ce sera le sujet du chapitre suivant.
Petit rappel sur RNIS
On ne sait jamais ! Peut-être que vous ne connaissez pas RNIS ! Je m’en voudrais de vous laisser dans l’expectative !
RNIS = Réseau Numérique à Intégration de Service. En anglais on parle d’ISDN (Integrated Service Data Network). C’est un réseau développé dans les années 1990 amené à remplacer le réseau téléphonique analogique classique.
Dans la pratique il a complètement supplanté le RTC (Réseau Téléphonique Commuté) classique auprès des entreprises, mais n’a pas percé auprès des particuliers.
En dehors du fait qu’il offre une numérisation des communications depuis le site client (contrairement à l’analogique qui n’était « numérisé » qu’à l’arrivée au central télécom), il offre de très nombreux services.
Je n’ai pas l’intention de vous faire un cours sur RNIS, vous trouverez facilement sur le Web de quoi étancher votre soif si nécessaire. Ce qui nous importe ici c’est :
– sa structure en canaux B à 64 Kbps
– les typologies d’accès T0 et T2
Vous pouvez souscrire deux types d’accès RNIS :
– l’accès T0 propose deux canaux (circuits) de communication simultanés à un débit de 64 Kbps (appelés canaux B) et un canal de signalisation à 16 Kbps (appelé canal D). Si l’on cumule le débit des deux canaux B on peut donc obtenir une connexion à 128 Kbps au maximum sur un accès T0.
– l’accès T2 propose 30 canaux B à 64 Kbps et un canal D à 64 Kbps pour la signalisation. En cumulant le débit des 30 canaux B vous pouvez donc (en théorie) obtenir une connexion à 1920 Kbps.
N’oublions pas que ces accès relèvent du monde téléphonique ! Un accès possède donc un numéro (de téléphone) et il est nécessaire de numéroter pour entrer en communication avec un correspondant.
Vous pouvez associer des séquences de numéros à un même accès. Ainsi vous pourriez donner 5 numéros à un T0 (01.46.46.10.00 à 05 par exemple). On appelle cela une SDA (Sélection Directe à l’Arrivée). Cette SDA peut ainsi être répartie entre 5 postes sur le bus S (derrière la TNR : Terminal Numérique de Réseau).
Si vous souhaitez pouvoir émettre 6 communications simultanément, vous pouvez commander plusieurs T0 (ici il vous en faut 3, car 3*2 canaux B = 6 canaux !). Ces accès peuvent être montés en groupement d’accès et associés à une seule séquence SDA …
Enfin au-delà de 12 canaux (6 T0) il est préférable de commander un T2. Vous pouvez très bien commander un T2 mais n’y prendre que 15 canaux sur les 30. La facturation de l’opérateur s’opère au canal. A ce T2 vous pouvez bien sûr associer une séquence SDA (50 numéros par exemple). A noter qu’un T2 sera généralement connecté à un équipement capable de gérer un grand nombre de lignes. Dans le cas d’une utilisation pour le service téléphonique il sera connecté à un PABX (Private Branch Exchange). Dans le cas d’un réseau informatique il pourra être connecté à un NAS (Network Access Server) ou un routeur. Nous y reviendrons …
Pourquoi avoir plus de numéros que de canaux possibles ? Parce que tout le monde ne téléphone pas en même temps ! Vous pouvez très bien avoir 30 personnes dans votre entreprise (donc 30 numéros) mais ne jamais avoir plus de 10 communications en même temps !
Le schéma ci-après tente de synthétiser mes propos !
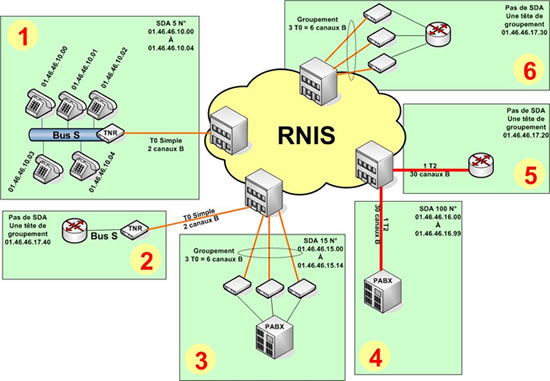
Le cas 1 : permet avec un accès de 2 canaux B (deux communications simultanées) d’adresser 5 postes téléphoniques grâce à la SDA de 5 numéros.
Le cas 2 : permet d’obtenir un débit de support maximum de 128 Kbps en cumulant les deux canaux B. Une séquence SDA est inutile puisqu’il s’agit de joindre uniquement un seul équipement (le routeur). A noter que le routeur est installé derrière la TNR et devra présenter une interface S0 pour se connecter au Bus RNIS. Chez Cisco vous utiliserez des cartes WIC-1B-S/T, WIC-2B-S/T, NM-4B-S/T ou NM-8B-S/T selon le nombre d’accès T0/S0 à connecter.
Le cas 3 : permet de connecter un groupement de T0 (ici 3) à un PABX. Ce PABX pourra desservir jusque 15 postes grâce à la séquence de SDA 15 numéros associée. Bien sûr il ne pourra y avoir au maximum que 6 communications simultanées.
Le cas 4 : présente le raccordement d’un PABX par un T2 offrant 30 canaux B. Il est associé à une séquence SDA de 100 numéros et peut donc servir 100 postes. Mais seulement 30 communications simultanées.
Le cas 5 : présente un routeur connecté à un T2 offrant 30 canaux B. Le débit maximum possible sera donc de 1920 Kbps en cumulant tous les canaux B. Cet accès est uniquement associé à un numéro (dit Tête de groupement) car il y a un seul équipement à adresser. Le routeur doit être équipé d’une interface T2. Chez Cisco vous utiliserez des interfaces NM-1A-E1 ou NM-1A-2E1 selon le nombre de T2 à raccorder.
Le cas 6 : permet de connecter un groupement de T0 (ici 3) à un routeur. Ce routeur disposera au maximum d’un débit de 384 Kbps égal à 6 fois 64 Kbps (6 canaux B). Cet accès est uniquement associé à un numéro (dit Tête de groupement) car il y a un seul équipement à adresser.
Vous en savez maintenant suffisamment pour passer à la suite …
Grands principes
Comme indiqué précédemment, cette méthode permet de secourir à la fois la liaison d’accès au réseau, le réseau lui-même et même la liaison d’accès au site de destination. Le routeur qui détecte l’indisponibilité du parcours active la connexion RNIS vers son destinataire.
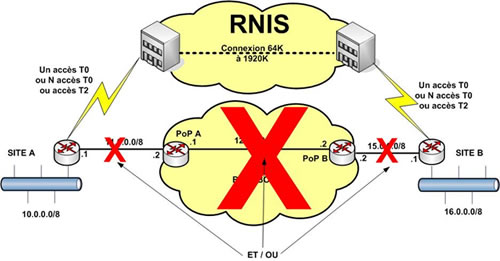
Les paramètres important dans cette configuration sont :
– le débit du lien RNIS de secours
– le principe d’activation du secours
– le principe du retour à la situation nominale
Le débit du lien RNIS
Il va directement dépendre du nombre de canaux B associé à chaque accès. Dans notre exemple, si le site A dispose de 3 T0 (donc 6 canaux B) et que le site B dispose seulement d’un T0, le débit maximum ne saurait excéder 128 Kbps (2 * 64 Kbps). Ce débit est donc déterminer à la conception du réseau en fonction de votre estimation du niveau de service acceptable en mode secours.
En effet, vous n’êtes pas obligé de fournir en mode secours un débit identique au mode nominal. Par exemple, si vos deux raccordements réseaux permettent un échange à 2 Mbps entre les deux sites, vous pouvez très bien n’autoriser que 1 Mbps en secours (soit donc 15 canaux B). On appelle cela : la dégradation de service ! Vous avez donc des secours en mode dégradés et d’autres sans dégradation (au même débit que le débit nominal).
Ce choix de débit de secours va dépendre :
– de ce que peuvent supporter vos applications et vos utilisateurs (faites gaffe aux manifs !)
– de ce que le DSI est prêt à payer ! Forcément, un accès T2 (30 canaux B => 1920 Kbps) est plus cher qu’un T0 (2 canaux B => 128 Kbps) ! En plus les cartes routeurs et les chassis routeurs ne seront pas nécessairement les mêmes ! Un routeur supportant un T2 sera plus cher qu’un routeur supportant un T0 !
– de ce que la technique vous autorise … Par exemple, en France vous ne pouvez pas dépasser 1920 Kbps pour une seule connexion RNIS de bout en bout ! En effet, le réseau backbone RNIS n’a pas été conçu pour permettre des connexions « haut débit » d’un bout à l’autre du réseau. Il est prévu pour acheminer des connexions éparses (capillaires) réparties entre différents points du réseau. En standard vous ne pouvez pas dépasser un débit de 1 Mbps en connexion bout en bout dans le réseau ! Au-delà vous devez faire une demande spécifique à France Télécom afin qu’il vérifie la capacité du backbone à acheminer ce débit d’un point à un autre ! Ceci n’empêche pas, en standard, un site d’établir 5 communications simultanées à 384 Kbps (soit 5 * 6 canaux B => 1920 Kbps) mais avec 5 sites distants différents pas avec un seul site distant ! Donc si vos accès nominaux permettent un échange à 4 Mbps entre vos sites A et B, le secours RNIS vous limitera au mieux à un débit de secours de 1920 Kbps ! Vous aurez donc un secours dégradé à 50%. Cette limitation pourra vous amenez à choisir d’autres types de secours que nous verrons dans les chapitres suivants …
Bref ! Le choix du débit de secours est donc un délicat et délicieux compromis entre le supportable fonctionnel, le supportable financier et le possible technique ! Bon courage !
MultiLink PPP (dit MLPPP)
Dans mes propos précédents j’évoque constamment le cumul de canaux B pour obtenir un débit RNIS compris entre 128 Kbps (2 canaux B) et 1920 Kbps (30 canaux B). Malheureusement, ne comptez pas sur RNIS pour vous livrer un UNIQUE train binaire au débit correspondant ! Si vous établissez une communication à 128 Kbps entre deux sites, vous aurez 2 connexions à 64 Kbps et non pas 1 connexion à 128 Kbps !
Ce sera au routeur de mettre en œuvre une technique permettant de cumuler le débit de ces deux canaux … Comme il ne peut pas le faire au niveau 1 puisque celui-ci est livré par les TNR comme deux circuits distincts, il va le faire au niveau 2 !
Le protocole de niveau 2 PPP (Point to Point Protocol), permet d’implémenter une fonction dite de « MultiLink ». C’est-à-dire qu’il va gérer X connexions de niveau 2 comme une seule et même connexion ! Les paquets niveau 3 transmis seront placés chacun dans des trames associées indifféremment à n’importe quelle connexion de niveau 1 (canal B). Au final vous avez donc un débit de niveau 2 équivalent à X débit de niveau 1 (moins l’overhead des encapsulations bien sûr !).
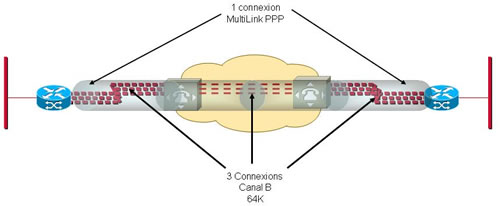
La fragmentation et le séquencement de paquets, comme spécifié dans le RFC 1717 (rendu obsolète par le RFC 1990), scindent la charge de PPP et envoient des fragments sur des circuits parallèles. Dans ce cas précis, ce « faisceau » de tubes Multilink PPP fonctionne comme une seule liaison logique, améliorant le débit et réduisant la latence entre routeur homologues.
Je n’entrerai pas dans le détail du fonctionnement MultiLink (adressage du trunck, séquencement trames et trunck, reprise sur erreur, etc …), mais sachez que cette procédure est tout de même assez consommatrice en ressource et nécessite parfois d’augmenter les performances des équipements la mettant en œuvre …
L’activation du secours
Nous avons précédemment étudié le principe de détection d’indisponibilité du lien ou du réseau nous partons donc du principe que notre routeur de site A est informé de l’indisponibilité du parcours (local ou distant). Il peut donc engager la procédure de bascule sur le lien de secours (ici le lien RNIS). Il est ici important de se pencher sur quatre aspects :
– le type de secours (secours de lien « physique » ou secours par routage)
– la temporisation d’activation et filtrage ou sélection du trafic
– la notion de maître – esclave (ou call-back)
– la notion d’identification
Type de secours
Nous avons vu dans le chapitre « Détection d’indisponibilité » que le routeur du site A pouvait détecter trois types d’indisponibilités :
– l’indisponibilité de sa liaison nominale de raccordement
– l’indisponibilité du backbone de rattachement
– l’indisponibilité d’un site distant
Dans le premier cas, on ne fera généralement pas appel à un protocole de routage. Le routeur détectera localement la perte du niveau 2 (PPP ou HDLC) et informera sa table de routage que la destination est hors service.
Toutefois, nombre d’équipements (notamment chez Cisco) permettent de « lier » par programmation deux interfaces en définissant l’une d’elles comme secours de l’autre. Chez Cisco la commande utilisée est « backup interface type numéro ». Dans la programmation de l’interface nominale (LL par exemple) vous définissez ainsi l’interface de secours. Ce mode permet donc de basculer très rapidement et sans protocole de routage sur l’interface RNIS de secours. Nous sommes donc dans un mode que j’appelle « secours de lien physique ».
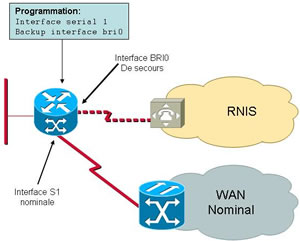
Si les capacités de programmation de votre routeur ne vous permettent pas d’implémenter un « secours physique », vous utiliserez le mode « secours par routage » pour suppléer à l’indisponibilité d’un lien de raccordement direct. En effet, l’indisponibilité du lien de raccordement entraînera nécessairement le passage « down » des routes associées dans la table de routage. Donc, si vous avez décrit une route de secours dans cette table, elle sera activée …
Dans les cas d’indisponibilité du backbone ou du site distant nous avons vu qu’il nous fallait compter sur les updates d’un protocole de routage pour nous informer du problème (sauf pour les réseaux Frame Relay qui utilisent le protocole LMI). Le routeur du site A basculera donc sur le lien de secours sur commande de sa table de routage. Ceci implique que dans la table de routage il existe donc deux lignes de programmation pour une même destination. Dans l’exemple ci-dessous, sur le routeur A nous avons :
– la route nominale : 11.0.0.0 via 12.0.0.2 sur S1 => tout trafic externe à envoyer au routeur 12.0.0.1 point d’entrée du backbone IP.
– la route de secours : par exemple 11.0.0.0 via 14.0.0.2 sur BRI0 => tout trafic externe à envoyer au routeur 14.0.0.2 accessible via la liaison RNIS connectée à l’interface BRI0 (BRI = Basic Rate Interface)
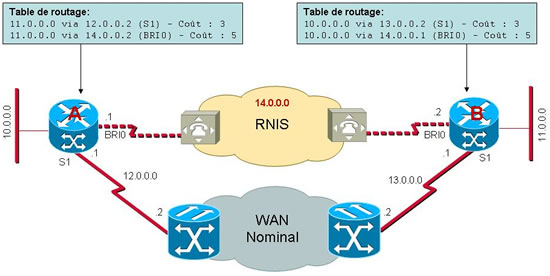
Remarque : vous noterez que l’adresse réseau 14.0.0.0 est affecté à l’ensemble du réseau RNIS ici. Chaque routeur qui serait connecté à ce réseau aurait donc une adresse 14.x.x.x (ici A a l’adresse 14.0.0.1 et B l’adresse 14.0.0.2). En effet RNIS est un réseau physique comme pourrait l’être un réseau Frame Relay ou LL. Alors que sur le WAN IP, nous avons donné des adresses réseaux différentes pour chaque lien d’entrée, car nous sommes sur un réseau de niveau 3.
Vous êtes toutefois des personnes avisées ! Vous avez sans doute remarqué qu’il y avait un petit problème ! Pour une même destination deux routes sont décrites dans la table de routage … Laquelle le routeur choisira-t-il ? S’il choisi systématiquement la route RNIS, vous allez écoper d’une belle facture en fin de mois !
Il vous faudra donc implémenter une notion de coût ! Je vous renvoie à l’excellent cours « Routage IP » pour vous rafraîchir la mémoire si nécessaire. Vous donnerez donc un coût supérieur à la route via RNIS de manière à être certain que la route nominale sera choisie en priorité si elle est disponible. Dans le schéma précédent vous voyez que la route nominale a un coût de 3 alors que la route RNIS a un coût de 5.
Dans les deux derniers cas nous sommes donc dans ce que j’appelle « un secours par routage ». A noter que ce mode est nettement moins réactif que le premier car il faut attendre les déclarations « down » des routes nominales ce qui selon les protocoles de routage peut prendre un certain temps. Rappelez-vous la notion de latence définie dans le toujours excellent cours « Routage IP» !
Temporisation d’activation et filtrage de trafic
Ces deux notions ne semblent à priori pas avoir de rapport et pourtant c’est le bien le cas ! N’oublions pas que RNIS est un réseau à établissement de circuits de type téléphonique. Le coût de revient de ce réseau s’établit sur 3 paramètres :
– l’abonnement d’accès au réseau facturé forfaitairement en fonction du type d’accès et du nombre de canaux souscrits
– le coût de la communication en fonction de sa durée (en secondes généralement)
– le coût de la communication en fonction de sa distance (une communication internationale est plus chère qu’un communication locale !)
Si on active une communication RNIS dès que le routeur détecte une indisponibilité du parcours nominal et qu’on la coupe seulement au rétablissement de la liaison nominale, on peut être confronté à une belle facture de communication au final (va pas être content le DAF !).
On peut donc avoir une approche plus mesurée ! On pourrait déjà n’établir la communication que si le site doit émettre des données ! Après tout si la coupure a lieu la nuit alors que personne ne travaille sur ce site ce n’est peut-être pas utile de jeter l’argent par les fenêtres … En plus on les connaît ces opérateurs ! Pour les faire travailler la nuit sur le rétablissement du lien nominal ce n’est pas gagné ! Au final on va activer et payer une communication pendant plusieurs heures pour rien !
Mais « Émission de données » par le routeur, ne veut pas forcément dire « Données utiles » ! Par exemple, si RIP est implémenté sur votre routeur (parce qu’en mode nominal il échange des updates avec d’autres routeurs (voir le cours Routage Niv. 1). Votre routeur émet donc potentiellement des updates RIP sur toutes ses interfaces (donc l’interface RNIS également) toutes les 30 secondes ! Est-ce vraiment utile ? Ne serait-il pas judicieux de sélectionner uniquement le trafic en provenance du LAN (donc de machines « utilisateur ») pour justifier de l’activation du lien de secours ?
On peut aussi pousser le raisonnement plus loin … En mode nominal le routeur échange des données avec l’ensemble des sites du réseau peut-être qu’en mode secours on peut se contenter de n’établir la liaison de secours que lorsque du trafic doit être émis vers un seul site (site central par exemple) ou un nombre restreint de sites. Dans ce cas on peut ne sélectionner que le trafic à destination de certaines adresses IP destination.
En synthèse :
– on temporise l’activation de la connexion RNIS de secours jusqu’à ce que du trafic à émettre se présente
– on sélectionne (filtre) le type de trafic susceptible de générer la connexion RNIS
Tous les routeurs offrent des commandes/fonctions de sélection/filtrage de trafic et temporisation d’activation de connexion. Toutefois nous démontrerons par la suite que dans les faits il n’est pas si évident de pouvoir limiter la connexion sur ces critères.
Maître – esclave et Call-back
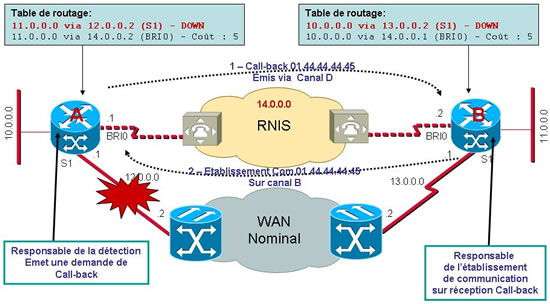
Cette considération n’est utile que dans un mode de secours « bout en bout » mettant en relation directement deux routeurs.
Nous avons démontré précédemment que les deux routeurs de notre réseau étaient chacun en mesure de détecter l’indisponibilité de leur parcours nominal. Dans ce cas, qui est responsable de l’activation du lien de secours ? Si les deux décident simultanément d’établir une communication de secours on sera confronté à un croisement des connexions (dans le meilleur des cas) ou (dans le pire des cas) à non établissement de communication car l’autre extrémité est occupé (en train de numéroter !).
Dans l’absolu il est donc nécessaire d’avoir un routeur responsable de l’établissement de la communication (le maître) tandis que l’autre ne fait que recevoir (l’esclave). Ceci permet également de définir quel site paiera les coûts de communication (après tout, le site isolé appartient peut-être à une société partenaire et non pas au titulaire du réseau central !). Dans la programmation d’un routeur on peut donc définir qui est maître ou esclave.
Toutefois ceci n’est pas totalement obligatoire car en RNIS les communications s’établissent par une signalisation préalable sur Canal D (alors que la connexion de Data est établie sur Canal B). Donc il est possible à deux routeurs (de la même marque ! Largement conseillé !) de s’accorder sur qui établira la communication en cas de conflit d’appel. Il est même possible à un routeur esclave de demander au routeur maître d’établir une communication car l’esclave a des données à lui émettre ou appelle ce mode le « Call-back » ! Vive le canal D !
Identification
RNIS c’est chouette ! Mais c’est quand même un réseau public ! Si je connecte un de mes routeurs à ce réseau pour disposer d’une solution de secours, qu’est-ce qui me garanti qu’il n’y aura pas un petit malin (mal intentionné !) qui ne cherchera pas à établir une communication avec mon routeur pour s’introduire dans mon réseau ?
Heureusement les équipementiers sont des gens avisés ! Ils ont prévus deux niveaux de sécurité (au minimum) :
– l’identification du numéro appelant : lorsqu’un routeur établi une communication (pas seulement un routeur d’ailleurs ! N’importe quel équipement sur RNIS !) le réseau RNIS communique (via le canal D) le numéro de l’appelant (numéro de téléphone !). Il est donc possible d’indiquer au routeur appelé de n’accepter les appels que depuis certains numéros. C’est déjà un bon niveau de sécurité car le numéro appelant est fixé par le réseau opérateur RNIS, il est donc difficile de le changer …
– l’authentification PAP/CHAP : En réseau et plus généralement en informatique on est parano (souvent à juste titre !), donc plus on est « secure » mieux c’est ! L’identification de l’appelant est donc renforcée par une authentification protocolaire. PAP/CHAP (Password Authentication Protocol : Protocole d’authentification de mot de passe / Challenge Handshake Authentication Protocol : Protocole d’authentification par tests) sont deux mécanismes du protocole PPP (procédure de niveau 2 qui se met en place sur la connexion de niveau 1 correspondant au canal B … Vive OSI !) qui permet d’authentifier les partenaires d’une connexion PPP. Pour faire simple, ils permettent l’échange d’un mot de passe (qui aura été configuré dans chaque routeur) avant de valider la connexion. En PAP l’échange est en clair (non crypté) en CHAP l’échange est crypté grâce à un nombre aléatoire (le challenge !) communiqué par l’appelé au moment de la demande de connexion.
Avec ces deux mécanismes nous sommes en mesure de garantir que la connexion à nos routeurs via RNIS ne pourra pas se faire … facilement ! Mais rien n’empêche d’ajouter d’autres mécanismes de sécurité au niveau applicatif (histoire d’être vraiment sûr !).
Où en sommes-nous ?
1 – Mes routeurs ont détecté l’indisponibilité du lien
2 – Le routeur maître (défini suite à ma programmation) a détecté du trafic valide (correspondant à mon filtrage) à émettre.
3 – Il a lancé une communication vers le routeur indiqué comme son correspondant de secours (programmation). S’il est en mode call-back il a lancé une demande de rappel (call-back : appel en retour) vers son routeur de secours.
4 – Le routeur appelé a accepté l’appel RNIS (ou la demande de call-back) car il provient d’un numéro reconnu (programmation) transmis par le Canal D. Ils ont donc établi une communication de niveau 1 sur le(s) canal(aux) B.
5 – Ils ont ensuite vérifié ensemble leurs identités via le protocole PAP/CHAP du protocole PPP (via le Canal B) et ont conclut qu’ils pouvaient valider la connexion PPP de niveau 2.
Les données de niveau 3 (paquets IP) peuvent enfin être acheminées … L’activation du secours est complète.
Délai d’activation et perte de trafic
En se référant à la description précédente on voit que l’activation d’un secours RNIS va prendre un certain temps, d’autant plus long si on active un « secours par routage ». Pendant ce temps, il n’y a plus de route disponible pour délivrer les paquets qui se présentent au routeur. Que se passe-t-il ?
Première phase : la route est hors service mais le routeur ne le sait pas encore (délai de transmission de l’information, notamment en mode routage). Dans ce cas il transfère les paquets sur l’interface normale et ceux-ci sont perdus …
Deuxième phase : le routeur sait que la route est indisponible mais n’a pas encore de solution de secours active. Il bufférise un peu les paquets et envoie à l’émetteur des paquets ICMP « Destination unreachable ». Charge à l’émetteur de calmer ses ardeurs s’il a la bonne idée d’interpréter les messages ICMP. Toutefois, le routeur n’a pas vocation à buffériser du trafic en attendant la disponibilité du lien de secours, ses buffers sont là pour temporiser un trafic notamment en cas de congestion mais pas pour stocker du trafic en attente de secours. Au final, les paquets reçus seront probablement perdus (écrasement buffer ou expiration du TTL => voir le cours IP).
On voit donc que la bascule en mode secours engendrera inévitablement une perte de paquets IP. Heureusement ces pertes seront détectées par les couches supérieures (par exemple TCP), mais IP lui-même n’a aucun mécanisme pour s’affranchir de ce problème. La couche TCP de l’émetteur procédera donc à une réémission des segments non reçus par le destinataire ce qui engendrera du point de vue de l’utilisateur un ralentissement momentané tout à fait perceptible.
Une activation rapide du secours est donc la bienvenue, mais nous devons également considérer les temporisations nécessaires à la mise à jour des routages ou la stabilité du réseau. Un choix difficile … On privilégiera les temporisations plutôt que d’activer le secours dès qu’il y a une micro-coupure sur le lien nominal. Sans cela le remède pourrait être pire que le mal en engendra des instabilités récurentes des routes et des reconfigurations incessantes des tables de routage. De plus n’oublions pas qu’en principe nous sommes dans un mode « exceptionnel ». On active pas le secours tous les jours … Ou alors changez vite d’opérateur !
Désactivation du secours
Il y a deux grands cas de désactivation de la connexion RNIS de secours :
1 – Il n’y a plus de trafic à router sur cette liaison de secours.
2 – Le parcours nominal ayant nécessité le passage en secours est revenu à l’état normal. On peut donc de nouveau envoyer les paquets sur le parcours normal.
Premier cas : Plus de trafic à router
Nous avons vu précédemment que pour éviter d’établir la connexion de secours de manière prolongée sans intérêt, nous placions des filtres de détection de trafic « utile ». Si le routeur ne reçoit plus ce type de trafic il pourra déconnecter la liaison RNIS pour économiser le coût de communication.
Bien sûr il s’agira de définir une temporisation d’attente car il n’est pas question de connecter / déconnecter le canal RNIS de manière incessante. Ceci générerai des instabilités dans le réseau et un délai d’acheminement du trafic difficilement supportable par l’utilisateur (une connexion RNIS mettra au moins deux secondes à s’établir). Un bon délai de temporisation d’attente serait d’environ 5 minutes.
Deuxième cas : Le parcours nominal redevient opérationnel
Dans la configuration « secours physique de lien », le routeur va détecter le retour du lien nominal par la réactivation successive des niveau 1 puis 2 OSI. Lorsque la connexion niveau 2 est opérationnelle, le routeur commande la déconnexion de l’interface RNIS de secours associée (en mode backup interface) et place la route nominale en mode « up » dans la table de routage. Généralement dans ce mode on associera également une temporisation de déconnexion car il ne s’agirait pas de commander une déconnexion du lien RNIS pour un retour à la normale fugitif du lien nominal.
Dans une configuration « secours par routage », le routeur reçoit des informations de retour du parcours nominal à la normale via des updates du protocole de routage. Ceci replace donc la route nominale à l’état « up » dans la table de routage. Comme cette route a un coût plus intéressant que la route de secours tout le trafic est de nouveau émis sur le lien nominal. Ceci implique que l’interface RNIS ne reçoit plus de trafic à émettre et donc se déconnectera comme indiqué dans le cas « Plus de trafic à router ».
Désactivation et double route
Vous noterez qu’il existe un certain délai entre le moment où la route nominale est de nouveau en service et le moment où le routeur déconnecte la connexion RNIS de secours. Pendant ce temps le routeur dispose donc de deux possibilités pour acheminer le trafic. Ce n’est pas vraiment un problème car IP ne se soucie pas du séquencement des paquets. Le paquet X peut avoir été acheminé par le lien de secours, et le paquet X+1 par le lien nominal. Ce dernier étant souvent d’un rendement (débit, délai d’acheminement) supérieur au lien de secours il est possible que P+1 arrive à destination avant P, mais la station réceptrice réordonnera les paquets (voir le cours IP).
Par contre, si vous êtes en mode « secours par routage » il est vraiment important que les deux routes aient des coûts différents favorisant le lien nominal. Sinon vous risquez d’entrer dans un mode de partage de charge (le routeur émet un paquet sur un lien puis un autre sur l’autre) qui générera du trafic sur le lien RNIS et empêchera sa déconnexion !
Les limites du secours RNIS bout en bout
A la sortie de ce chapitre tout à l’air pour le mieux. Nous avons réussi à implémenter une solution de secours permettant à un site de s’affranchir d’un problème sur sa liaison de raccordement, sur le backbone ou sur le site distant. Le secours dit « bout en bout » semble donc optimum … Mais cherchons un peu plus loin !
Problème 1 : Les réseaux « any to any »
Un réseau « any to any » sous entend que tous les sites d’un réseau peuvent (ou ont besoin … nuance non anodine !) échanger entre eux. Ceci s’oppose à un réseau dit « hub and spoke » (ou étoilé « in french »). Je vous renvoie au cours « Réseaux mutualisés » pour un petit raffraichissement sur les principales architectures de réseau.
Dans notre cas supposons que notre site A active une connexion RNIS bout en bout avec un site central B. Par contre il a besoin d’échanger des données également avec un site C qui lui est connecté « normalement » au réseau (et donc accède à B via le backbone). Comment va-t-il procéder ?
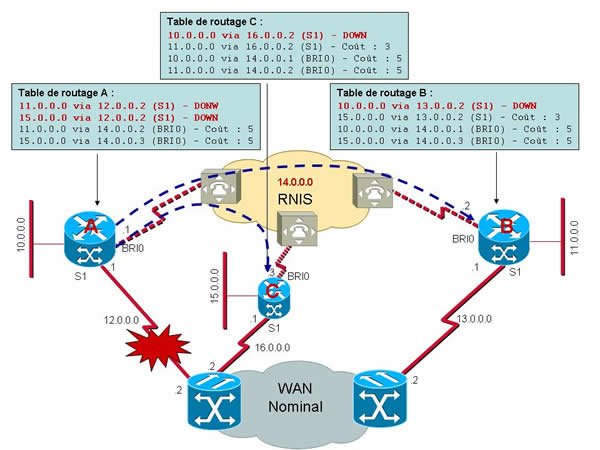
La mauvaise solution serait d’avoir prévu une double connexion RNIS de secours. Il vous suffit pour cela de décrire 2 routes distinctes dans la table de routage du routeur. Une pour établir une connexion RNIS vers B et une vers C. Ces deux routes devront avoir des coûts inférieurs aux routes nominales respectives et devront chacune pointer vers une interface RNIS spécifique du routeur (Attention : Concept très variable selon les équipementiers …). C’est donc techniquement tout à fait réalisable, mais c’est un cauchemar en terme de dimensionnement, en terme de coût et en terme d’exploitation. Vous allez multiplier les interfaces RNIS sur votre routeur ce qui implique une augmentation du coût du routeur, des abonnements RNIS et des consommations en cas d’activation. Si pour contacter deux sites simultanément c’est encore envisageable, le dimensionnement pour atteindre 10, 20 ou 50 sites risque d’être carrément cauchemardesque ! Quand à l’exploitation, je vous laisse imaginer la tête de votre table de routage (et de la programmation associée) pour réaliser ce type de secours sur 50 sites …
Il est donc plutôt préférable de pointer vers un seul site. On choisira généralement de laisser l’initiative de l’activation du secours au site distant (sous entendu site « client » d’un site serveur) vers un site de rattachement central. Lorsque la connexion RNIS sera établie, ce site assurera le transfert des informations vers le site C via sa propre liaison nominale.
Problème 2 : Le dimensionnement central
Nous venons d’indiquer qu’il est préférable que les sites distants établissent leur connexion RNIS de secours vers un site de rattachement, généralement le site central. C’est exact … Mais ceci pose une question : Combien de site distants peuvent potentiellement établir simultanément une connexion RNIS de secours ? Et accessoirement chacune de ces connexions est à quel débit ?
En effet, supposons que nous ayons un réseau de 50 sites distants équipés d’un secours bout en bout vers un site central unique … Si chacun d’eux établi une connexion à 64 Kbps en secours (débit ridicule de nos jours) le site central devra pouvoir recevoir 50 * 64 Kbps. Le routeur devrait donc être équipé de 2 interfaces T2 (30 canaux par T2). C’est cher ça ! Bon ! Ceux qui suivent vont me dire « C’est pour du secours ! Tous les sites distants ne vont pas être Hors service en même temps ! ». Et je vais répondre « Tout à fait ! Bravo ! Mais vous oubliez que nous étudions également le cas d’activation du secours en cas d’interruption backbone ou liaison distante, sous entendu liaison centrale ! Ca vous interloque là ? ».
Ceci implique une remarque importante : La notion d’activation de secours est une considération locale. Ceci veut dire qu’un site n’activera un secours qu’en cas d’indisponibilité de son raccordement local, c’est-à-dire sa liaison de raccordement ou le PoP de raccordement au backbone. Le site ne prendra pas en considération les cas d’indisponibilité des sites distants ou du backbone. Le secours du backbone est de responsabilité opérateur, le secours du site distant est de responsabilité … du site distant ! Sinon vous entrez dans des problèmatiques extrêmement complexes. Cette remarque est vraie quelque soit les modes de secours que nous verrons ultérieurement.
Ce problème écarté, il reste toujours la question d’évaluer le nombre de sites potentiellement en mode secours simultanément et le débit RNIS correspondant à implémenter coté site central. Ici il n’y a pas de recette miracle ! Il faut avoir une double approche :
1 – Quel est le débit de secours distant maximum à secourir ? En effet, sur 50 sites distants, vous pourriez très bien avoir 40 sites à 64 Kbps et 10 sites à 512 Kbps. Ceci implique donc que votre site central devra déjà au minimum disposer d’une connexion RNIS à 512 Kbps, ce qui lui permettra d’assurer le secours d’un site à 512 Kbps ou de 8 sites à 64 Kps.
2 – Combien de sites peuvent simultanément passer en mode secours ? Ceci dépendra beaucoup de la fiabilité de votre opérateur ! Il n’y a aucune approche statistique fiable ! Un peu d’expérience me porte à conseiller un taux maximum de 10% de connexions secours simultanées. Toutefois il est préférable d’avoir cette approche par grande classe de débit. Vous regroupez les sites de débit compris entre 64 et 256K, ceux compris entre 512K et 1M et enfin ceux au-delà. Après cela vous prenez un peu de hauteur, de flair et vous adaptez !
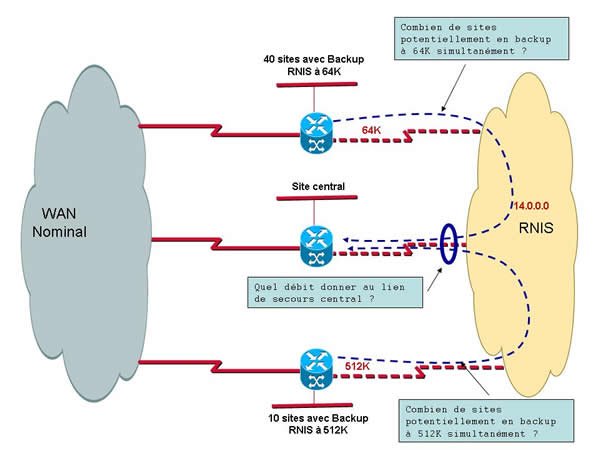
Au final si l’on applique ces conseils à notre configuration de 50 sites dont 40 secourus à 64 Kbps et 10 secourus à 512 Kbps on obtient :
– Débit de secours minimum : 512 Kbps
– Débit de secours statistiques : 10% de 40 (sites à 64 Kbps) + 10% de 10 (sites à 512 Kbps) = 4*64 Kbps + 1*512 Kbps
– Il vous faut donc un débit RNIS central équivalent à 768 Kbps (256 + 512) soit 12 canaux B.
– Vous devrait donc choisir un accès de type T2 (jusque 30 canaux) avec un abonnement de 12 canaux ou un groupement de 6 accès T0 (financièrement l’option T2 devrait être la meilleure). Il faut bien sûr que votre routeur central soit équipé des interfaces nécessaires.
On voit que tout cela n’est pas simple ! Si par malheur vous avez deux sites 512 Kbps qui passent en secours vous ne pourrez pas assurer leur secours simultané !
Je vous conseille donc de partir sur une option 16 canaux (1024 Kbps) permettant ainsi d’assurer deux 512 Kbps ou un 512 Kbps + 8 sites 64 Kbps. C’est ici que le flair s’applique !
Mais nous n’en avons pas fini avec le dimensionnement du site central ! Tout à l’heure nous avons évoqué la possibilité offerte au site A de joindre le site C en passant par le lien nominal du site B, son site de rattachement de secours. Ceci implique donc que le lien nominal de B va véhiculer du trafic A <=> C que normalement il ne supporte pas ! Ce lien a-t-il été dimensionné pour cela ?
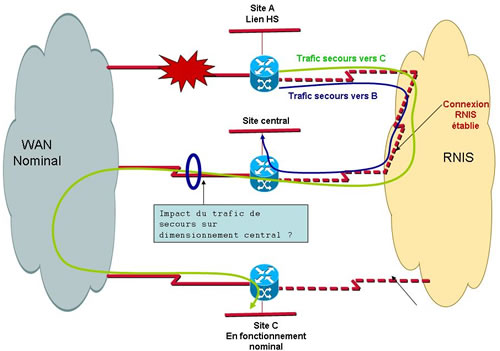
Dans l’absolu on peut penser que ce n’est pas trop grave, puisque par compensation ce lien n’a plus à supporter le trafic A <=> B initial (celui-ci passant maintenant par le lien RNIS de secours). Toutefois si en fait le site A discutait beaucoup avec le site C et peu avec le site B il est possible que le dimensionnement du lien nominal de B ait été calculé avec un poids faible du trafic en provenance de A. Donc en assurant le transfert A <=> C il risque une surcharge. Ceci milite donc pour bien choisir le site de rattachement de secours. Il doit impérativement être celui qui est en mode nominal le site central du trafic pour le site considéré. Le problème est que ceci n’est pas forcément homogène au sein d’un réseau. On voit courrament des agences régionales discutant majoritairement avec leur Direction Régionale et assez peu avec le siège central parisien (un peu de chauvinisme !). Par contre ces mêmes Directions Régionales auront un trafic soutenu avec le siège. C’est la notion de réseau « hiérarchique » développée dans le cours « Réseaux mutualisés ». Il serait donc bienvenue d’avoir un secours des agences vers leur direction de rattachement et un secours des directions vers le siège …
Vous le voyez ce n’est vraiment pas simple à dimensionner !
Problème 3 : Le coût variable
Lorsque vous les aurez côtoyé un petit moment vous apprendrez une chose. Un DAF aime avoir une prédictibilité des coûts. Il budgétise ! Il demande donc au DSI de lui indiquer le plus précisément possible le coût de revient de son réseau (et d’un tas d’autres choses d’ailleurs). Du coup le DSI devient comme le DAF ! Il veut un budget prédictible et contrôlé pour son réseau ! Le problème du secours RNIS c’est qu’une partie du coût est fonction de l’usage (le coût de communication). En plus, ce coût va varier en fonction de la distance ! Une communication Versailles – Paris n’a pas le même coût minute qu’une communication Marseille – Paris ou pire New-York – Paris !
Quand la communication est locale et que de plus elle ne s’établit que rarement parce que votre lien de raccordement est fiable, le coût est négligeable. Par contre si vous établissez régulièrement des connexions de secours internationales ceci peut ne plus être neutre !
Avec le secours RNIS bout en bout il est malheureusement impossible de forfaitiser le coût du secours sauf si vous arrivez à négocier avec votre opérateur la prise en charge de ces coût de secours (après tout c’est de sa faute si le secours s’active !).
En conclusion
Le secours RNIS bout en bout est aujourd’hui désuet pour les raisons évoquées précédemment :
- débit de secours relativement limité
- dimensionnement central difficile à définir
- architecture absolument pas adaptée à des réseaux « any to any »
- coût d’usage non prédictible et non forfaitaire.
Dans le chapitre suivant nous allons donc étudier une évolution permettant de répondre à la majorité de ces critiques. Il s’agit du secours RNIS par NAS.
Page Précédente | Page Suivante